Bloodraven
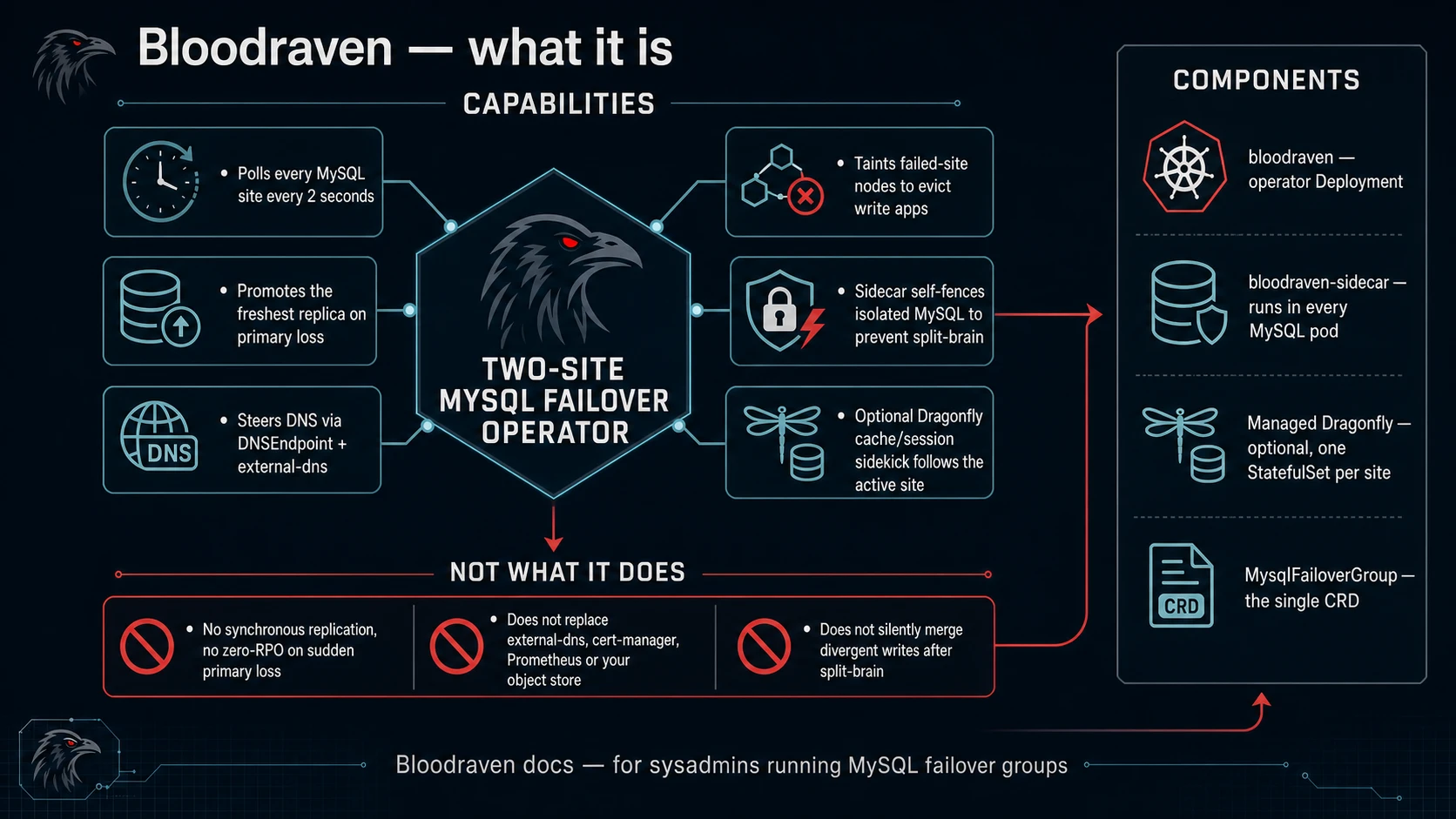
Bloodraven is a Kubernetes operator for MySQL async replication failover groups across sites. It automates failover detection, promotion, DNS steering, application workload migration, and optional Dragonfly cache/session sidekicks that follow the active MySQL site so a site-level outage can recover without human intervention.
Who this is for
| Reader | Use these docs to |
|---|---|
| New user | Try Bloodraven locally and create a first failover group. |
| Platform operator | Install the operator, define production guardrails, and run go-live checks. |
| Application developer | Connect safely and handle failover reconnect behavior. |
| On-call responder | Map alerts to runbooks and verify recovery under pressure. |
| Backup owner | Configure, verify, and restore backups without reading the full CRD reference first. |
What Bloodraven does not do
- It does not provide synchronous replication or zero RPO after sudden primary loss.
- It does not replace external-dns, cert-manager, Prometheus, Grafana, or your object store.
- It does not make application connection pools failover-aware automatically.
- It does not reconcile divergent writes for you after split-brain.
- It does not make PVC-local backups durable after cluster or storage loss.
- It does not treat Dragonfly as durable application storage; managed Dragonfly is for cache/session continuity.
User journeys
| Journey | Path |
|---|---|
| New user | Getting Started → Playground → App Integration |
| Platform operator | Production Install → Production Hardening → Monitoring |
| On-call | Operations Overview → Failure Mode Matrix → Runbooks |
| Backup owner | Backup Overview → S3 or PVC → Verification → Restore |
Standout features
- Automatic MySQL site failover: If the active MySQL site dies, Bloodraven promotes another site, moves traffic, updates DNS, and helps the old primary rejoin safely.
- Split-brain protection: If two sites might both accept writes, the operator and sidecars fence unsafe MySQL nodes so the cluster does not keep writing in two places.
- Graceful planned switchover: An admin can move the primary site with one command; Bloodraven waits for the replica to catch up first, so planned moves can have zero data loss.
- Backup, restore, PITR, and verification: Bloodraven can create backups, archive binlogs for point-in-time recovery, encrypt artifacts, restore from them, and test backups by loading them into a throwaway MySQL.
- Dragonfly cache/session failover: Bloodraven can manage Dragonfly alongside MySQL, move the active cache/session endpoint during failover, and try to preserve sessions during planned moves.
- Chaos-tested in CI: 30+ automated chaos scenarios — primary kills, network partitions, split-brain, self-fencing, data wipes, backup/PITR verification — run against real Kubernetes clusters nightly, and a smoke subset gates every release before artifacts are published. The same playground runs locally so you can test these failure modes yourself before you trust them in production.
Using an AI agent? This documentation is available as llms.txt and llms-full.txt at the site root for consumption by LLM-based tools. Give your agent context with a prompt like:
Read https://bloodraven.readthedocs.io/en/latest/llms-full.txt and help me configure a MysqlFailoverGroup for two sites with async replication and automatic DNS failover.
:::info When to use Bloodraven Bloodraven targets the two-site, accept-non-zero-RPO deployment. If you need synchronous writes and zero RPO on primary loss, read Why not Group Replication? first to make sure the tradeoffs match your use case. :::
Components
| Component | Description |
|---|---|
bloodraven | The operator binary. Runs as a Deployment, watches MysqlFailoverGroup CRs, reconciles MySQL state. |
bloodraven-sidecar | Runs alongside each MySQL container. Provides health probes and self-fencing when the operator is unreachable. |
| Managed Dragonfly | Optional per-site Dragonfly pods created when spec.dragonfly.enabled=true. Applications use the active dragonfly Service for Redis-compatible cache/session traffic. |
Custom resource
Bloodraven introduces a single CRD:
MysqlFailoverGroup(shipstream.io/v1alpha1) -- Declares MySQL instances across named sites, their storage, networking, DNS, transport layer security (TLS), failover tuning, and optional Dragonfly co-management.
apiVersion: shipstream.io/v1alpha1
kind: MysqlFailoverGroup
metadata:
name: orders
spec:
credentials:
operatorSecret: mysql-operator-creds
appSecret: mysql-app-creds
dns:
hostname: orders.az.example.com
ttl: 60
sites:
- name: iad
zone: us-east-1a
taintNodeSelector:
shipstream.io/failover-group.orders: "true"
shipstream.io/site.orders: iad
lbIP: 10.0.1.1
storage:
size: 50Gi
storageClassName: gp3
- name: pdx
zone: us-west-2a
taintNodeSelector:
shipstream.io/failover-group.orders: "true"
shipstream.io/site.orders: pdx
lbIP: 10.0.2.1
storage:
size: 50Gi
storageClassName: gp3
Next steps
- Architecture -- How the operator, sidecars, MySQL instances, and optional Dragonfly sidekicks interact.
- Getting Started -- Install the operator and create your first failover group.
- Production Install -- Production dependencies, Helm values, CRD ownership, and verification.
- Playground -- Try Bloodraven locally on k3d, kind, or minikube with a live dashboard and chaos tools.
- Backup Overview -- Choose S3 or PVC, configure schedules, and verify recoverability.
- Runbooks -- Incident response entry points.
- CRD Reference -- Complete spec and status field reference.