Alert To Runbook Map
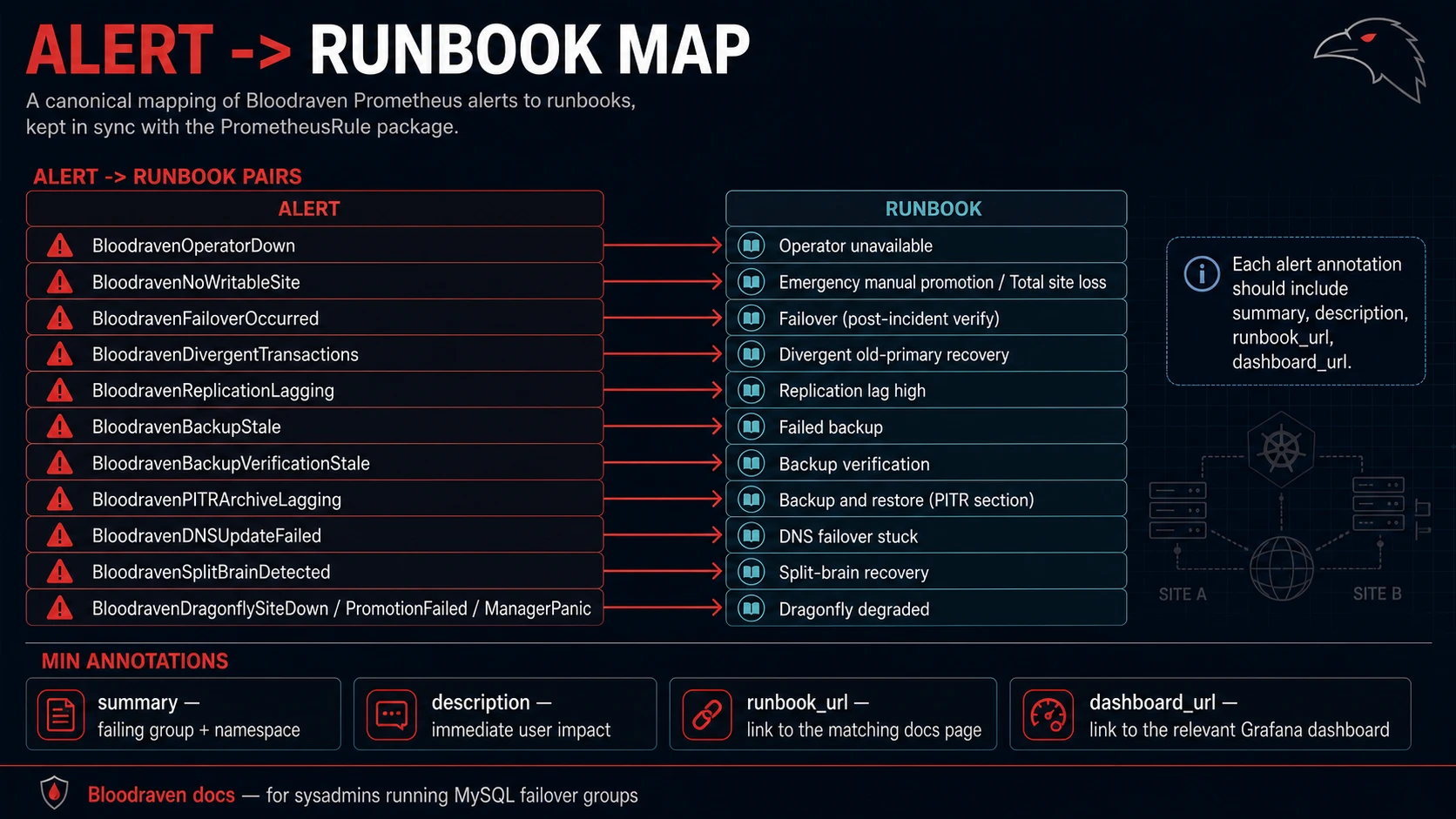
Keep this table synchronized with your PrometheusRule package. Alert annotations should link to the matching page or heading. Use the Observability Change Checklist when adding, removing, or changing alerts, alert annotations, runbook links, dashboard links, or actionable Events.
Alerts
| Alert | Primary runbook | First checks |
|---|---|---|
BloodravenOperatorDown | Operator unavailable | Deployment, leader election, logs |
BloodravenNoWritableSite | Emergency manual promotion or Total site loss | Active site, pod reachability, fencing |
BloodravenFailoverOccurred | Failover | DNS, app writes, old primary state |
BloodravenDivergentTransactions | Divergent old primary recovery | Events, GTIDs, old primary fenced |
BloodravenReplicationLagging | Replication lag high | lag metric, MySQL replica status |
BloodravenBackupStale | Failed backup | latest MysqlBackup, Job logs |
BloodravenBackupVerificationStale | Backup Verification | verification CRs, restore logs |
BloodravenPITRArchiveLagging | Backup And Restore | archiver metrics, object storage |
BloodravenDNSUpdateFailed | DNS failover stuck | DNSEndpoint, external-dns logs |
BloodravenSplitBrainDetected | Split-brain recovery | writable sites, app traffic, GTIDs |
BloodravenDragonflySiteDown | Dragonfly degraded | status.dragonfly.sites[], Dragonfly pods, active Service endpoints |
BloodravenDragonflyPromotionFailed | Dragonfly degraded | planned-failover Dragonfly status, Events, Redis client impact |
BloodravenDragonflyManagerPanic | Dragonfly degraded | operator logs, panic counter, current status.dragonfly |
Kubernetes Events
| Event category | Expected operator action | Runbook |
|---|---|---|
| Planned failover requested/started/completed | Drain writes, promote target, update DNS | Planned Failover |
| Emergency failover started/completed | Promote best candidate, taint old site, update DNS | Failover |
| Reclone started/completed/failed | Rebuild replica from active primary | Divergent old primary recovery |
| Backup started/completed/failed | Create/update MysqlBackup Job and status | Failed backup |
| Restore started/completed/failed | Gate bootstrap or restore workflow | Failed restore |
| Verification started/completed/failed | Restore backup into ephemeral MySQL | Backup Verification |
| DNS update created/failed | Write DNSEndpoint for external-dns | DNS failover stuck |
| Split-brain or recovery pending | Fence losers or wait for manual recovery | Split-brain recovery |
| Dragonfly promotion/sync/upgrade events | Preserve or restore cache/session continuity while MySQL remains authoritative | Dragonfly degraded |
Minimum alert annotations
Each alert should include:
summarywith the failing group and namespace.descriptionwith immediate user impact.runbook_urlpointing to this docs site.dashboard_urlpointing to the relevant Grafana dashboard.
If an alert intentionally has no runbook or dashboard link, the change must include a specific operational rationale in the pull request. Do not use a bare N/A.