Architecture
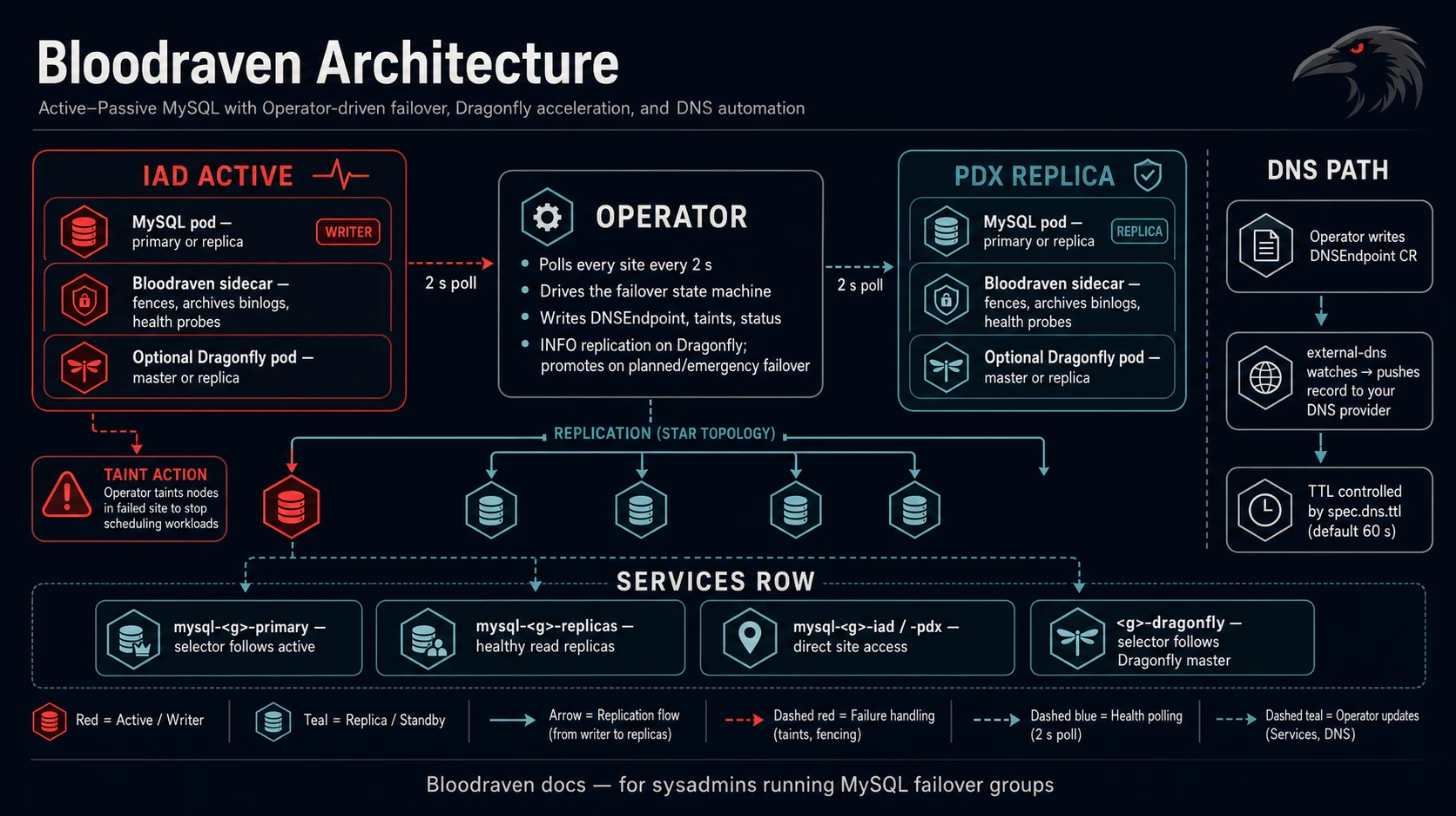
Bloodraven manages MySQL async replication failover groups. Each MysqlFailoverGroup resource describes two or more sites, each running a MySQL pod with a sidecar container. When spec.dragonfly.enabled=true, each site also gets a single-replica Dragonfly StatefulSet that acts as a cache/session sidekick for the same failover group. Sites carry explicit roles — primary-candidate (promotable on failover) or dr-only (passive replica) — and at least two primary-candidate sites are required so an active primary always has a promotion target. The operator continuously polls every site and takes corrective action when the topology deviates from the desired state.
Bloodraven uses a star replication topology for MySQL: one site is the active primary, and every other site replicates from it. Managed Dragonfly uses the same active-site model: one Dragonfly pod is the master, and non-active sites are configured as replicas of that master. There are no replication chains. See Multi-site topology for the full role model and sizing guidance.
High-level overview
Operator (bloodraven)
The operator runs as a single-replica Deployment with controller-runtime
leader election enabled as a safety belt. See
Operator availability for the complete
breakdown of what happens — and what doesn't — when the operator is
down. For each MysqlFailoverGroup, it:
- Creates a MySQL Deployment, Service, and PVC per site
- Creates a
mysql-<name>-primaryService whose selector tracks the active site - Creates a
mysql-<name>-replicasService whose selector matches healthy read replicas - Runs a polling loop (default 2s) that connects to each site's MySQL instance and evaluates the replication topology
- Applies the state machine logic to decide whether to failover, alert, or do nothing
- On failover, executes the failover sequence including DNSEndpoint updates and node tainting
- When Dragonfly is enabled, creates per-site Dragonfly StatefulSets and Services, observes
INFO replication, keeps replicas attached to the active master, and promotes Dragonfly during planned and emergency failover
The operator exposes:
- Prometheus metrics on
:8080/metrics - Health probes on an auxiliary port
- Status API on
:8082(GET /status,GET /active-site,GET /ws/status)
Sidecar (bloodraven-sidecar)
Each MySQL pod includes a sidecar container that:
- Responds to health and readiness probes
- Monitors connectivity to both the operator and every peer site (the sidecar is given a comma-separated list of peer sidecar addresses at pod-spec time)
- Self-fences on topology mismatch: every
peerCheckIntervaltick the sidecar polls the operator'sGET /active-siteendpoint. If the operator-authoritative active site is a different site than this one and MySQL is still writable, the sidecar fences immediately regardless of lease timing. When the operator is unreachable to this sidecar but reachable to a peer, the sidecar also reads the peer's cached view viaGET /peer/active-siteand adopts it when strictly newer than its own. This closes the gap where a stale primary returns after a failover: even if the peer is reachable (so the lease-only rule would never fire), the mismatchedactiveSitetriggers an immediate fence. - Self-fences on full isolation as a backstop: if the operator AND every peer are unreachable for
leaseTimeout(default20s), it setsSET GLOBAL super_read_only=ONon its local MySQL instance. A single reachable peer is enough to keep the primary writable under this rule. - Startup safety net: on boot, queries the operator's
GET /active-siteendpoint to determine the current active site. The sidecar fences MySQL first and only clearssuper_read_onlyif the operator confirms this is the active site; the answer also seeds the shared topology cache so/peer/active-siteis usable from tick zero. - Binlog archiver (PITR): when
spec.backup.pitr.enabled=true, a goroutine watchesmysql-bin.indexvia inotify and uploads each sealed binlog to the referenced backup profile's storage. Only the primary uploads (gated on@@read_only); after a failover the new primary's archiver takes over within one scan cycle. Archived files are pruned once the oldest retainedMysqlBackupmoves past them, using a cutoff timestamp pulled from the operator's/pitr-cutoffendpoint. See Backup and restore → PITR.
This self-fencing behavior is a critical safety net. Even if the operator is down, an isolated MySQL instance will not accept writes that could diverge from the other site. The full timing of operator-down + primary-failure is documented in Operator availability.
Architectural note: the archiver runs in the sidecar rather than the operator because inotify + direct binlog file reads need the MySQL data PVC mounted. PVCs are typically ReadWriteOnce and bound to one node, so a centralized archiver in the operator pod can't mount every failover group's data volume. The sidecar is already per-pod and already knows its local MySQL's role, so it's the natural home.
Services
Each MysqlFailoverGroup named orders produces these Services:
| Service | Purpose |
|---|---|
mysql-orders-iad | Direct access to the iad site MySQL instance |
mysql-orders-pdx | Direct access to the pdx site MySQL instance |
mysql-orders-primary | Follows the active primary. Apps connect here for writes. |
mysql-orders-replicas | Matches healthy read replicas. Apps connect here for reads. |
The -primary and -replicas Services use label selectors that the operator updates when the topology changes. See App Integration for connection details.
When spec.dragonfly.enabled=true, the group also produces these Dragonfly Services:
| Service | Purpose |
|---|---|
orders-dragonfly-iad | Direct access to the iad Dragonfly pod for replication wiring and debugging. |
orders-dragonfly-pdx | Direct access to the pdx Dragonfly pod for replication wiring and debugging. |
orders-dragonfly | Redis-compatible application endpoint. Selects only the pod labeled shipstream.io/dragonfly-role=master and shipstream.io/dragonfly-traffic=enabled. |
The active Dragonfly Service does not use DNS steering. Its endpoint set changes when the operator updates role and traffic labels during planned failover, emergency failover, Dragonfly-only promotion, or Dragonfly image rollout.
PodDisruptionBudget
Each failover group gets a PodDisruptionBudget named mysql-<name> with minAvailable: 1. This ensures at least one MySQL instance remains running during voluntary disruptions such as node drains and cluster upgrades.
When spec.dragonfly.enabled=true, the operator also creates one Dragonfly PodDisruptionBudget per site named <name>-dragonfly-<site> with minAvailable: 1. These PDBs do not make Dragonfly durable, but they avoid voluntary disruptions taking a site's cache/session pod down during routine node drains.
Labels
All resources managed by the operator carry a standard set of labels:
| Label | Value |
|---|---|
app.kubernetes.io/name | mysql |
app.kubernetes.io/instance | <failover-group-name> |
shipstream.io/failover-group | <failover-group-name> |
shipstream.io/site | <site-name> |
app.kubernetes.io/managed-by | bloodraven |
Pods receive additional labels:
| Label | Value |
|---|---|
shipstream.io/role | primary or replica |
shipstream.io/healthy | yes or no |
These labels drive Service selectors and can be used for monitoring queries and policy rules.
Dragonfly resources use the same app.kubernetes.io/instance, shipstream.io/failover-group, shipstream.io/site, and app.kubernetes.io/managed-by labels, with app.kubernetes.io/name=dragonfly. Dragonfly pods also receive shipstream.io/dragonfly-role (master or replica) and shipstream.io/dragonfly-traffic=enabled; the active Service selector requires both dragonfly-role=master and dragonfly-traffic=enabled.
Replication topology
Bloodraven uses MySQL asynchronous replication with GTID-based positioning. At any given time:
- One site is the primary (
read_only=0,super_read_only=0) and accepts writes - The other site is the replica (
read_only=1) and replicates from the primary
The operator does not configure multi-source replication or group replication. It manages a simple primary-replica pair and handles promotion and demotion through direct SQL commands.
When Dragonfly is enabled, Bloodraven treats it as cache/session state rather than durable application data. Planned failover waits for the target Dragonfly replica to catch up and then promotes it with REPLTAKEOVER. Emergency failover attempts Dragonfly promotion best-effort within a bounded budget; if Dragonfly cannot preserve sessions, MySQL failover still completes.