Backup verification
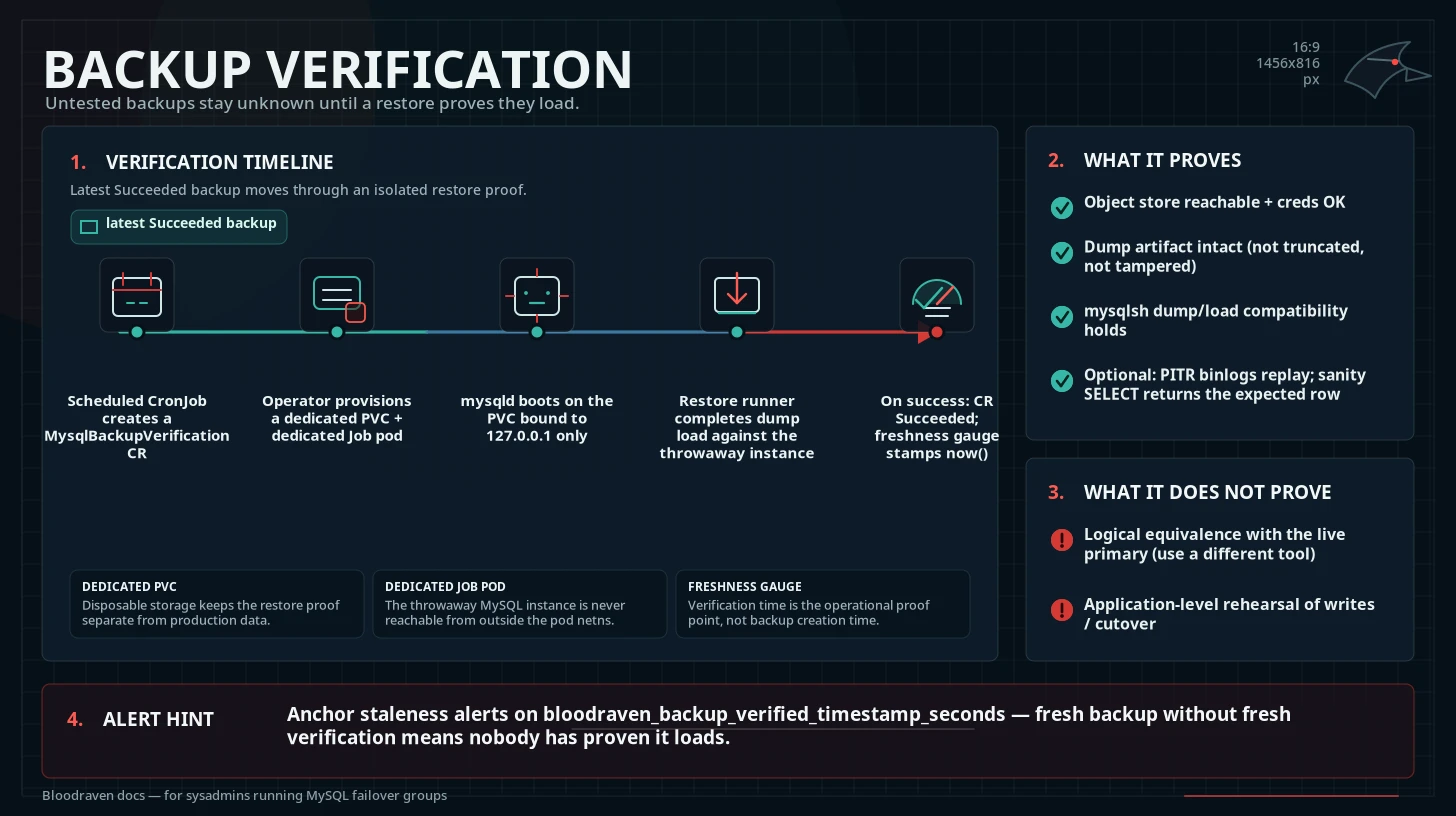
An untested backup is a schrödinger backup — it is both good and bad until you try to restore it, which you usually do during the incident that made you reach for it. Bloodraven's verification feature closes that loop: it periodically restores the most recent successful backup into a throwaway MySQL instance to prove the backup is actually loadable, and exports a freshness gauge so alerting can fire on stale or broken verifications.
Phase 1 established the CRD and the dump-load contract. Phase 2 layers
PITR binlog replay and configurable scalar sanity queries on top of the
same CRD. See WISHLIST.md #8 for remaining roadmap items (kubectl
plugin integration, Grafana panels).
Concepts
MysqlBackupVerificationCRD — one CR per verification run. Created ad-hoc viakubectl createor by the scheduled CronJob that the operator renders from a profile'sverificationblock. Tracks phase, start/completion times, resolved backup reference, and the names of the ephemeral Pod / Job / PVC used for the run.- Verification schedule —
spec.backup.profiles[].verificationon the failover group. Whenenabled: true, the operator materializes a CronJob whose pod runsbloodraven trigger-verificationto create aMysqlBackupVerificationCR. - Ephemeral instance — each run provisions a dedicated PVC
and a dedicated Job pod. The pod boots
mysqldon the PVC with--bind-address=127.0.0.1, then delegates the actualutil.loadDump()to the sharedrestore.pyscript against that local instance. No external Service is created; the verification instance is never reachable from outside the pod network namespace.
What counts as "verified"
The default verification contract is the backup dump loads into an
empty mysqld without error. That covers the failure modes that cause
most real disasters — corrupt object store, truncated dump,
missing credential rotation, storage class regression, mysqlsh version
incompatibility. When you also set spec.pointInTime or
spec.sanityCheck the contract extends to "archived binlogs replay on
top of the dump" and "a caller-supplied SELECT returns a result that
matches an expectation," respectively.
The feature deliberately does not cover:
- Logical equivalence with the live primary (a different tool).
- Backup encryption decryption (wishlist #13).
- Application-level rehearsal of writes / traffic cutover (wishlist #7, #11).
Scheduling a verification
Attach a verification block to any BackupProfile:
apiVersion: shipstream.io/v1alpha1
kind: MysqlFailoverGroup
metadata:
name: orders
spec:
backup:
image: container-registry.oracle.com/mysql/community-server:9.7
profiles:
- name: nightly
storage:
type: S3
s3:
bucket: orders-backups
prefix: nightly
region: us-east-2
credentialsSecret: orders-backups-creds
retentionPolicy:
count: 14
minKeep: 3
verification:
enabled: true
schedule: "0 5 * * *" # after the 02:00 backup finishes
concurrencyPolicy: Forbid
storage:
storageClassName: fast-ssd # optional; defaults to cluster default
retentionPolicy:
keepSuccessful: 30 # keep last 30 Succeeded runs
keepFailures: 10 # always keep last 10 Failed runs
The operator reconciles this into a CronJob named
mysql-<group>-verify-<profile> whose pod invokes bloodraven trigger-verification --group=<group> --profile=<profile>. That
subcommand creates a MysqlBackupVerification CR, which the
verification reconciler picks up.
Use concurrencyPolicy: Forbid (the default) unless you are
confident two verifications of the same profile can run side by side;
they cannot share a PVC and Allow just stacks failed runs.
Running a one-off verification
Any operator with permission to create MysqlBackupVerification CRs
can trigger an ad-hoc run:
kubectl create -f - <<'EOF'
apiVersion: shipstream.io/v1alpha1
kind: MysqlBackupVerification
metadata:
generateName: orders-nightly-drill-
namespace: bloodraven
spec:
failoverGroupRef: { name: orders }
profileName: nightly
# backupRef omitted → verifies the latest Succeeded MysqlBackup
# for (group=orders, profile=nightly).
EOF
To verify a specific historical backup:
spec:
failoverGroupRef: { name: orders }
profileName: nightly
backupRef:
name: orders-nightly-20260413-0200
PITR binlog replay
When the failover group has spec.backup.pitr.enabled: true, a
verification can confirm that the archived binlog stream replays
cleanly on top of the dump. Add spec.pointInTime:
spec:
failoverGroupRef: { name: orders }
profileName: nightly
pointInTime:
mode: latest # one of: none | latest | timestamp
mode: none(default) — no replay; equivalent to leavingpointInTimeunset.mode: latest— replay through the newest archived event. The operator wires abloodraven pitr-downloadinit container that downloads manifests + binlog files into an emptyDir, thenverify.shstreams them into the ephemeral mysqld viamysqlbinlog.mode: timestamp— replay stops just before the first event afterspec.pointInTime.timestamp(RFC3339).
On success, status.replayedThroughBinlog is populated with the last
applied file, position, and server-clock timestamp. The
bloodraven_backup_verification_replay_lag_seconds gauge is published
as completionTime − replayedThroughBinlog.timestamp; alert on a
threshold that matches your RPO target.
Sanity query
After the dump loads (and optional PITR replay succeeds), a single scalar-returning SELECT can be evaluated:
spec:
sanityCheck:
query: "SELECT COUNT(*) FROM orders.orders WHERE created_at > NOW() - INTERVAL 7 DAY"
expect:
minRows: 1 # optional; fails if the scalar is below this
maxDurationSeconds: 60
The verification records the scalar value in
status.sanityCheck.resultRow on success, or an error string on
failure. maxDurationSeconds is enforced with a client-side timeout;
exceeding it fails the run with reason SanityCheckTimeout, and a
query error or below-floor scalar fails with SanityCheckFailed.
Lifecycle
A verification CR passes through these phases:
| Phase | Meaning |
|---|---|
Pending | Accepted; finalizer stamped; no ephemeral resources yet. |
Provisioning | Ephemeral PVC + derived credentials Secret created. |
Restoring | The verification Job is running verify.sh + restore.py. |
Checking | Reserved for Phase 2 sanity queries; Phase 1 bypasses this phase. |
Cleaning | Reconciler is deleting ephemeral resources. |
Succeeded | Terminal success. Gauge advances; ephemeral resources cleaned up. |
Failed | Terminal failure. See KeepOnFailure below. |
On the happy path the CR goes Pending → Provisioning → Restoring → Succeeded. The ephemeral Pod, Job, Service-if-any, and PVC are deleted after an optional TTL.
Storage sizing
The ephemeral PVC is always dedicated per run and auto-sized from the
referenced backup's status.sizeBytes:
- Explicit
spec.storage.sizewins when set. - Otherwise:
max(10 GiB, ceil(1.5 × backupSizeBytes / 10 GiB) × 10 GiB). - The 1.5x multiplier gives MySQL headroom for indexes, temp files, and the occasional tablespace fragmentation that arises during load.
Override spec.storage.storageClassName when you want a faster class
than the cluster default; verification wall-clock time scales roughly
linearly with datadir write throughput.
Failure handling and keepOnFailure
On Succeeded, the ephemeral Pod and PVC are always deleted after
spec.ttlSecondsAfterFinished (default: immediately).
On Failed, the default (spec.keepOnFailure: true) leaves the Pod
and PVC in place so operators can kubectl exec into the verification
instance, tail its mysqld error log, or attach an interactive mysqlsh
session to inspect whatever the load got as far as. Failed
verifications are still GC'd by the retention sweep once they drop out
of the keepFailures window.
Set keepOnFailure: false on a one-off CR to force full cleanup even
on failure — useful for repeated-probe use cases where the
failure signal alone is what you care about.
Concurrency
The reconciler refuses to run two verifications against the same
(group, profile) pair simultaneously. Newer CRs land in Failed
with the BlockedByActiveVerification condition reason. Scheduled
runs use concurrencyPolicy: Forbid by default so this rejection is
rare; it mostly protects against kubectl create being issued right
as the nightly schedule fires.
Metrics
Verification metrics mirror the bloodraven_backup_* family and share
the (group, profile) label set:
| Metric | Type | Meaning |
|---|---|---|
bloodraven_backup_verified_timestamp_seconds | Gauge | Unix time of last Succeeded verification — the freshness gauge |
bloodraven_backup_verification_last_attempt_timestamp_seconds | Gauge | Unix time of last terminal attempt, success or failure |
bloodraven_backup_verification_runs_total | Counter | Terminal attempts by result="success" or result="failure" |
bloodraven_backup_verification_duration_seconds | Histogram | Wall-clock duration from StartTime to CompletionTime |
bloodraven_backup_verification_replay_lag_seconds | Gauge | completionTime − replayedThroughBinlog.timestamp (Succeeded + PITR) |
Alerts
The obvious alert is staleness on the freshness gauge:
# Verification hasn't Succeeded in more than 48h:
time() - bloodraven_backup_verified_timestamp_seconds > 48 * 3600
And a failure-rate alert for fast signal:
# More than 2 failed verifications in 24h:
increase(bloodraven_backup_verification_runs_total{result="failure"}[24h]) > 2
Inspecting results
kubectl get mysqlbackupverifications -A
# Group Profile Phase Started Completed Age
# orders nightly Succeeded 12m 2m 12m
kubectl describe mysqlbackupverification orders-nightly-20260420
# ... includes status.backupRef, status.durationSeconds, conditions
The CR's owner references point back at the MysqlFailoverGroup, so
deleting the group cascades through verifications along with the rest
of its managed state.
Security
- The verification Pod runs with the same hardened pod- and container-level SecurityContext as backup / restore Jobs (RunAsNonRoot, ReadOnlyRootFilesystem, RuntimeDefault seccomp, capability drop ALL).
- Credentials flow through files mounted under
/run/bloodraven/mysql-creds, never environment variables. - The ephemeral mysqld binds
127.0.0.1only — no Service is created, so the verification instance is not reachable from anywhere outside the Pod's network namespace.
Known limitations
- No backup encryption support — will follow wishlist #13.
- No
kubectl bloodraven verify-backupsubcommand yet — will follow wishlist #18. - The
Checkingphase value is defined in the CRD enum but the reconciler does not currently transition through it at runtime; the sanity query runs inside the same Job container as the restore and the phase goesRestoring → Succeeded|Faileddirectly. Sanity results land onstatus.sanityCheckeither way.