Durability and RPO
Bloodraven drives asynchronous primary→replica replication. The primary commits locally and sends binlog events to the replica; it does not wait for the replica to persist those events before returning success to the application. That single design choice is what gives Bloodraven its sub-second write latency and its ability to keep serving writes when the replica is down — and it's also the sole reason the RPO of an emergency failover is not zero.
This page makes the RPO contract explicit so you don't have to infer it from source code.
The contract in one line
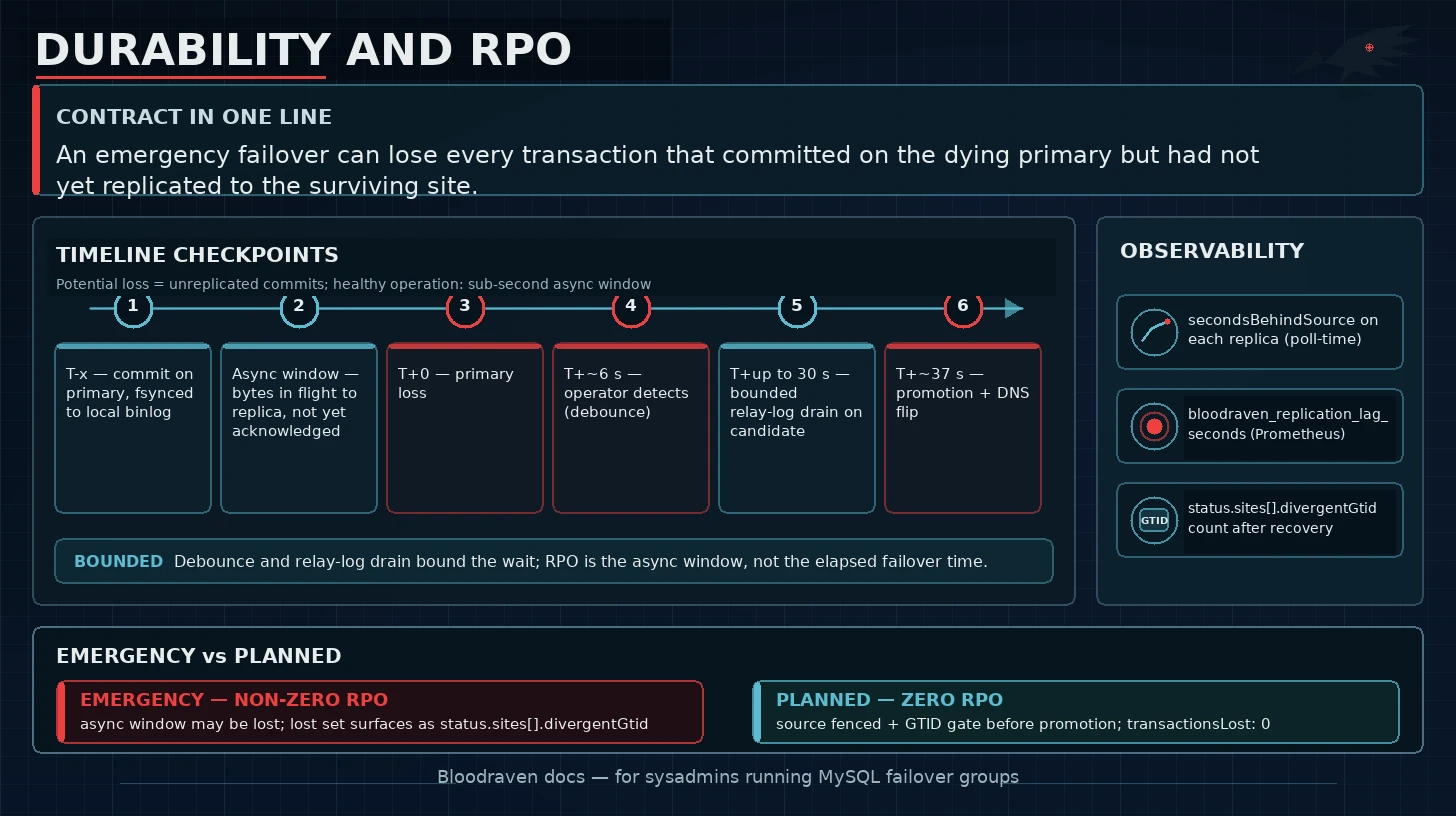
An emergency failover can lose every transaction that committed on the dying primary but had not yet replicated to the surviving site.
Everything below is the detail behind that sentence — the theoretical bound on how much can be lost, what the operator surfaces so you can audit it after the fact, and how Point-in-Time Recovery (PITR) interacts with the bound.
What gets persisted where
Bloodraven configures each MySQL pod with:
| Setting | Value | What it means for durability |
|---|---|---|
sync_binlog | 1 | Every committed transaction is fsync()ed to the primary's binary log before returning success to the client. A kernel panic on the primary does not lose acknowledged transactions from the primary's own disk. |
innodb_flush_log_at_trx_commit | 2 | InnoDB redo log is written to the OS on every commit but flushed to disk only once per second. On a power loss (not just a process crash), up to ~1 s of redo can be lost — but the binlog is still authoritative, so replay from a backup + binlog is unaffected. |
gtid_mode | ON | Every committed transaction has a globally-unique GTID. This is what lets status.sites[].divergentGtid be a set rather than a timestamp — you get a precise count of lost transactions, not an estimate. |
log_replica_updates | ON | Replica writes its replicated transactions back into its own binlog so it can itself become a primary after failover without re-replaying. |
max_binlog_size | 100M (configurable via spec.backup.pitr.maxBinlogSize) | Drives binlog rotation cadence, which is what PITR archival is bounded by. See PITR and RPO below. |
What this means for the primary-standalone case. If the primary
crashes but its PVC survives, MySQL restarts, the binlog tail is
rotated and sealed, and replication to the replica catches up. No
transactions are lost. The operator doesn't even need to fail over —
it observes the primary return to writable and keeps it as primary.
What this means for async replication. sync_binlog=1 makes the
primary's copy durable. It does not make the replica's copy
durable. Between the moment the primary commits and the moment the
replica's IO thread acknowledges receipt of those events, the bytes
exist only on the primary. If the primary (and its PVC) vanish in that
window, those transactions are unrecoverable from the replica.
The theoretical bound: seconds_behind_source
The strictest lower bound on RPO is the replication lag at the moment of failure. That lag is surfaced three ways:
status.sites[].secondsBehindSourceon theMysqlFailoverGroupCR (populated for the replica site on every poll).- The
bloodraven_replication_lag_secondsPrometheus gauge. SHOW REPLICA STATUScolumnSeconds_Behind_Sourceon the replica.
Typical value under healthy operation: < 1 second. Bloodraven polls
every 2 s (configurable via spec.pollInterval) and asserts replication
health on every poll; a replica that lags past
spec.replication.maxLagSeconds (default 300 s) transitions the CR's
Degraded condition to True with reason ReplicationLagging.
Concretely: if the replica was reporting secondsBehindSource=0 at
T−2s and the primary dies at T, the largest window of
unreplicated-committed work is bounded by how many transactions the
primary accepted in that ≤ 2 s interval. In practical throughput terms
this is "at most a few hundred transactions for a typical OLTP
workload", and in many real outages it is zero — the replica had
already seen every committed transaction.
Relay-log drain narrows the window further
Step 2 of the failover sequence is
a bounded-wait relay-log drain on the candidate: before the candidate
is promoted, the operator gives it up to 30 s to apply any relay-log
events the IO thread had already fetched but the SQL thread hadn't
processed. Transactions that made it across the wire to the replica
before the primary died are therefore not lost even if SQL_THREAD
was momentarily behind. The RPO window is specifically "transactions
the primary committed but the replica's IO thread never received" —
tighter than raw seconds_behind_source implies.
The exact bound: divergentGtid
seconds_behind_source is an estimate; GTIDs are authoritative.
After an emergency failover Bloodraven computes the exact set of
transactions that existed on the old primary but never made it to the
new primary, and writes the result into two CR status fields:
status.sites[<old-primary>].divergentGtid— the GTID set of lost transactions, in MySQL's compact range notation (e.g.a1b2c3d4-…:11-15).status.sites[<old-primary>].divergentTransactionCount— a simple count so you can alert on it without parsing the set.
The same value drives the RecoveryPending condition with reason
DivergentTransactions and the bloodraven_divergent_transactions
Prometheus gauge. Zero means "the replica had everything at the moment
the primary was fenced" — an RPO of 0 in this specific failover.
Non-zero means "this many transactions are permanently lost from the
replication stream unless you recover them out-of-band from the old
primary's binlog."
Bloodraven also records status.promotionGtidExecuted — the GTID
set on the new primary at the moment of promotion, before it began
accepting writes. Together with divergentGtid this gives you
a post-hoc audit of every failover: the promoted site started from
promotionGtidExecuted, and any GTIDs the old primary had beyond that
are enumerated in divergentGtid.
Per-failure-mode RPO matrix
| Failure mode | Replica state at failure | RPO |
|---|---|---|
| Pod crash, PVC survives, MySQL restarts in place | Any | 0 — operator sees the primary return writable before debounce fires; no failover happens. |
| Pod crash, PVC lost, operator triggers failover | Caught up (lag ≈ 0) | 0 — the exact moment-of-failure GTID lives on the replica; no transactions are unaccounted for. |
| Pod crash, PVC lost, operator triggers failover | Lagging (secondsBehindSource > 0) | ≤ lag value in seconds worth of transactions. Lost set is reported in divergentGtid. |
| Cross-site partition, operator promotes the reachable side | Depends on lag at moment of partition | ≤ lag at partition start. divergentGtid surfaces the exact set once both sites are observable again. |
Both sites unreachable (operator sees TotalLoss) | n/a | No failover occurs. RPO accumulates on the primary until at least one site comes back. See Operator availability. |
| Operator is down while the primary crashes | Depends on lag at crash | Same as the equivalent PVC-lost case — sidecars fence themselves, the replica is read-only, RPO is bounded by the lag at crash. Write-availability is also lost until the operator returns (see Operator availability), but RPO is not made worse by the operator being down. |
Split-brain (both sites writable) | Both have been accepting conflicting writes | RPO is undefined until a human picks an authoritative side; the losing side's divergent GTIDs are lost when that side is fenced and recloned. See Split-brain recovery. |
| Planned failover (admin annotation) | Target caught up to fenced source GTID before promotion | 0 — by construction. The zero-lag gate at WaitingForLag only advances once the target's GTID_EXECUTED ⊇ the source's fenced GTID_EXECUTED. Any scenario that would produce loss (lag never closes, source crashes mid-drain) routes to a Failed rollback instead of promoting a lagging replica. |
PITR and the RPO window
Point-in-Time Recovery, when enabled (spec.backup.pitr.enabled=true),
archives each sealed binlog file to S3 or a shared PVC as the
primary rotates. The archived binlogs are what a restore replays on
top of a full dump to reach an arbitrary stopDatetime. See
Point-in-time recovery
for the end-to-end story.
PITR narrows the worst-case RPO — but only inside a specific failure-mode envelope. The nuance:
- Archival is bounded by rotation cadence. The archiver uploads
every binlog except the currently-active one (the one MySQL is
still writing to). Rotation happens on size (
max_binlog_size, default100M), onFLUSH BINARY LOGS, or on restart. So at any moment on a healthy primary, the unarchived tail is at most one binlog file's worth of writes. - Pod crash with PVC survival → PITR recovers the tail. When MySQL restarts, it rotates the binlog, seals the previously-active one, and the archiver picks it up on the next scan. The previously-unarchived tail is now in storage. A PITR restore can replay up to the last committed transaction.
- PVC loss → PITR does not recover the tail. The previously-active
binlog lived on the destroyed PVC. It is gone forever, along with
any transactions it contained. This is the case the wishlist flagged:
"PITR narrows RPO to
max_binlog_sizerotation cadence only if the primary's binlog tail survives" — on PVC loss it doesn't. - PITR doesn't recover what async replication already lost. If you restore from the surviving replica's dump + archived binlogs, you are bounded by what the replica ever received. Transactions the old primary committed but never shipped are not in the replica's binlog stream and therefore not in PITR's replay material. Even a successful PITR restore cannot reach back beyond the async-replication cutoff.
Pragmatic takeaway. PITR is a disaster-recovery tool for rolling back time (restore to 14:32 before the bad migration) or for recovering from backup-artifact loss. It is not a mechanism for bringing the async-replication RPO below zero seconds. For that you would need synchronous replication, which is not in Bloodraven's design.
Cross-cluster recovery. PITR also powers the cross-cluster DR path:
when an entire cluster is lost, the DR cluster can bootstrap a new
MysqlFailoverGroup from the source's S3 dump archive with an optional
pointInTime replay window. The unarchived binlog tail on the lost PVC
is still unrecoverable, but the RPO is bounded to that tail — not the
entire last-backup interval. See
Multi-cluster DR for the end-to-end runbook.
Tuning: what you control
The relevant knobs for narrowing the async-replication RPO window, in order of impact:
- Keep
maxLagSecondstight. The shipped default of300s is generous to accommodate catch-up after network blips; if your SLO is stricter, lower it. A tighter value means theDegradedcondition fires sooner, so a human or an automation notices a lagging replica before the primary dies.cautionmaxLagSecondsis an alerting threshold, not a promotion gate. If the primary dies while the replica is beyond the threshold, Bloodraven still promotes the replica — the alternative of "no writable site at all" is almost always worse than a high-RPO failover. Treat a sustainedDegraded=Truewith reasonReplicationLaggingas a page. - Monitor
bloodraven_replication_lag_secondsand alert on sustained non-zero values. Sub-second lag is your normal; any drift upward is an early warning that the RPO on a future primary failure is growing. - Tune
spec.backup.pitr.maxBinlogSizeif you enable PITR and care about the non-PVC-loss case. Smaller rotation = smaller unarchived tail = tighter PITR RPO in the narrow case where the primary's PVC survives but you still want to do a point-in-time replay. The default100Mis a reasonable balance; going below10Mcosts you archival overhead without a meaningful RPO benefit on most workloads. - Use PVC storage that survives pod eviction. The most common way
to turn a pod-crash RPO-of-0 outage into a PVC-loss RPO-of-lag
outage is storage that doesn't survive a node failure. Use a
network-attached PV (EBS, Persistent Disk, Ceph RBD) rather than
hostPathoremptyDir, and confirm yourStorageClasshasreclaimPolicy: Retainfor the data PVC.
What you don't control from Bloodraven: application-side write
patterns. If your application is willing to accept "probably
committed" on a non-fsynced write path, no amount of operator
durability config can fix that. sync_binlog=1 (what Bloodraven
configures) is the strongest setting MySQL offers for primary-side
durability.
Related reading
- Failover → Old primary recovery
— how the operator surfaces
divergentGtidand how an admin runs the reclone interlock after an RPO-non-zero failover. - Operator availability → Operator-down + primary failure — why operator downtime doesn't make RPO worse, but does make write-availability worse.
- Backup and restore → Point-in-time recovery — the restore-side of the PITR story (the archiver side lives in Architecture → Sidecar).