Failover
This page covers the state machine that drives MySQL failover decisions, the exact sequence of operations during a failover, Dragonfly follow-along behavior when enabled, the anti-flap cooldown, and ordered updates for zero-downtime rollouts. For the bounded-RPO contract and the exact set of transactions that can be lost on emergency failover, see Durability and RPO. For what happens when the operator itself is unavailable during a failure, see Operator availability.
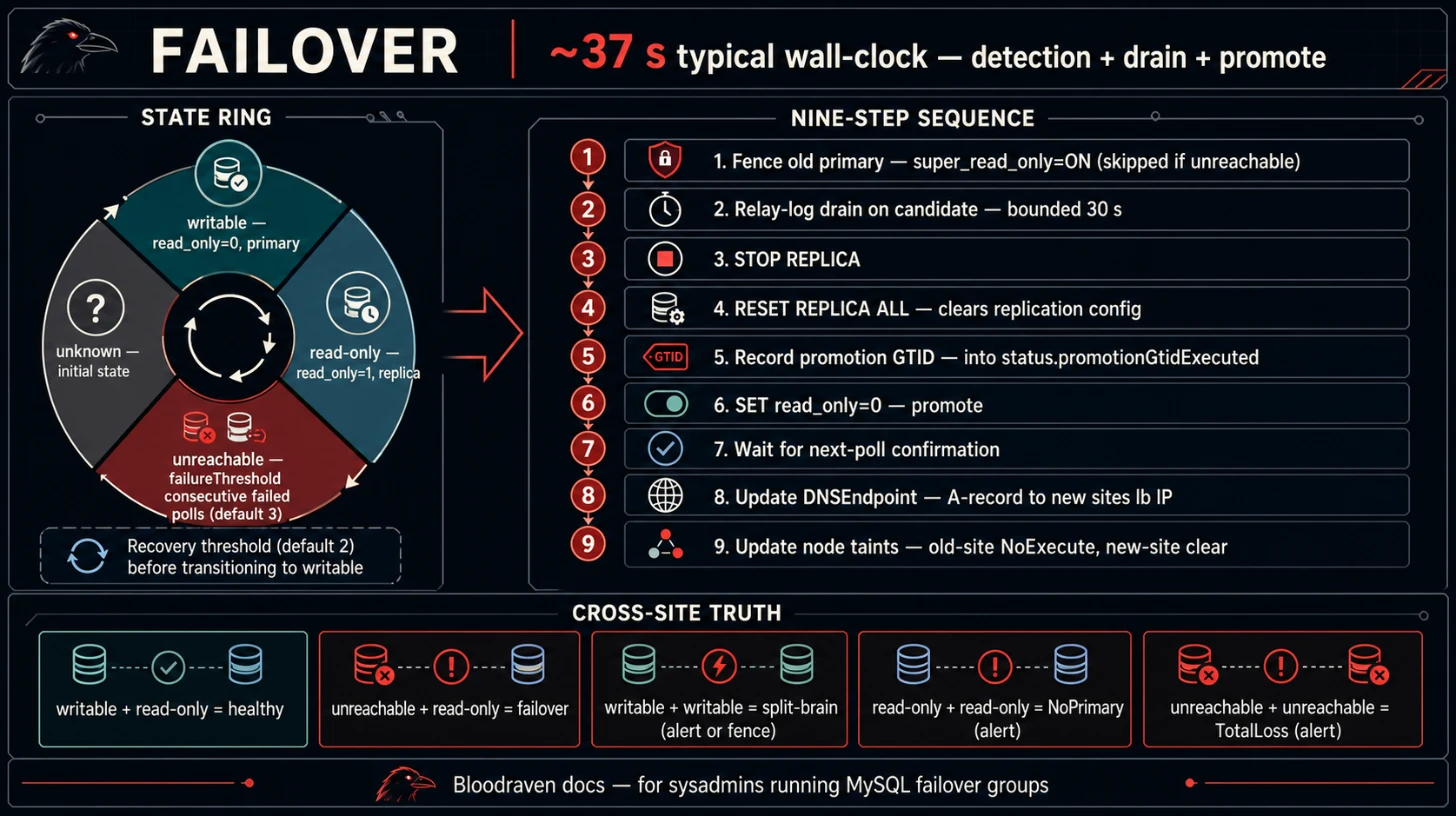
State machine
Each site in a failover group is tracked independently. The possible states are:
| State | Meaning |
|---|---|
unknown | Initial state before the first successful poll |
writable | MySQL is reachable and read_only=0 |
read-only | MySQL is reachable and read_only=1 |
unreachable | MySQL has failed the configured number of consecutive polls |
State transitions
Debouncing:
- A site transitions to
unreachableonly after failureThreshold consecutive failed polls (default: 3). With a 2-second poll interval, this means 6 seconds of downtime before the operator considers the site unreachable. - A site transitions to
writableonly after recoveryThreshold consecutive successful polls showingread_only=0(default: 2). This prevents premature promotion on transient successes. - Transitions to
read-onlyare immediate (single poll) since this is a safe, non-destructive state.
Cross-site evaluation
After updating individual site states, the operator evaluates the pair together:
| Site A | Site B | Action |
|---|---|---|
writable | read-only | Healthy -- no action needed |
unreachable | read-only | Failover -- promote Site B |
read-only | unreachable | Failover -- promote Site A |
writable | writable | Split brain -- see Split-brain resolution |
read-only | read-only | No primary -- alert, no automatic action (with one exception, below) |
unreachable | unreachable | Total loss -- alert, no automatic action |
The operator only takes automatic action for the failover case (and, opt-in, for split brain). All other anomalous states require human investigation.
The table is the two-candidate core reduced to two columns. In an N-site
group, only primary-candidate sites can be the active site, promotion target,
or split-brain winner. dr-only and read-only sites are non-promotable. A
writable non-promotable site is an anomaly and is fenced on every poll; a
reader is fenced even when it is the sole writable site. Reader outages and
replication failures remain visible per site but are excluded from group
readiness and degradation calculations. Readers never trigger node taint
changes or become active DNS targets.
Exception — re-asserting a fenced promoted primary. A freshly promoted primary can be fenced back to read-only by its own sidecar: the sidecar's fencing lease may still be stale when the promotion lands (for example, the operator restarted after a full-site outage and promoted before its auxiliary Service endpoint became Ready, so the sidecar's operator probes kept failing while the operator was already driving MySQL). That leaves every site reachable and read-only — a state the table above refuses to touch, because without history it is indistinguishable from a fresh-start condition that needs human input.
The operator, however, does have history: status.lastFailoverTarget names the site it made authoritative. When all of the following hold, the operator restores writability on that site instead of alerting and waiting:
- a prior failover is recorded and its target is reachable, read-only, and a
primary-candidate; - every other site is also reachable and read-only (an unreachable site hands the decision back to the normal failover row above);
- the target contains every other site's
GTID_EXECUTEDand the recordedstatus.promotionGtidExecuted— restoring it cannot lose transactions or create a second primary.
The re-assert is rate-limited to once per failoverCooldown, logs re-asserting fenced promoted primary (see the log schema), and increments bloodraven_primary_reassert_total. GTID divergence between the sites still blocks it — that genuinely needs a human.
Failover sequence
When the operator decides to fail over to a candidate site, it executes these steps in order:
-
Fence the old primary:
SET GLOBAL super_read_only=ON- If the old primary is unreachable, this step is skipped (it is already isolated)
-
Drain relay logs on the candidate (30-second timeout)
- Waits for the candidate to finish applying any relay log events so that no committed transactions are lost
-
Stop replication on the candidate:
STOP REPLICA -
Reset replication on the candidate:
RESET REPLICA ALL- Clears all replication configuration so the candidate operates as an independent primary
-
Record promotion GTID:
SELECT @@global.gtid_executed- Captures the candidate's GTID set before it starts accepting writes, stored in
status.promotionGtidExecutedfor data-loss accounting
- Captures the candidate's GTID set before it starts accepting writes, stored in
-
Promote the candidate:
SET GLOBAL read_only=0- Makes the candidate writable
-
Wait for confirmation
- The next poll cycle confirms the candidate is in the
writablestate
- The next poll cycle confirms the candidate is in the
-
Update DNSEndpoint
- Creates or updates the
DNSEndpointCR so that the A-record points to the candidate site's load balancer IP. external-dns syncs this to the configured DNS provider.
- Creates or updates the
-
Update node taints
- Taint old active site nodes:
shipstream.io/db-readonly-<group>=true:NoExecute - Untaint new active site nodes: remove the
shipstream.io/db-readonly-<group>taint
- Taint old active site nodes:
-
Converge every follower's source
- Candidate,
dr-only, andread-onlyfollowers are verified against the newly confirmed active primary - Each follower must replicate directly from the primary; replication chains are not accepted as converged
- Candidate,
Direct-source convergence
Source convergence runs after replica status collection and outside the
promotion sequence. It is therefore able to repair a healthy wrong source
after an operator restart even when no failover history exists. Mutation is
allowed only when there is exactly one writable primary-candidate, no second
writable site, and no bootstrap, update, restore, topology freeze, pending
promotion, planned failover, or split brain in flight.
For a wrong non-empty source, Bloodraven:
- Verifies that the active primary's
GTID_EXECUTEDcontains the follower's executed set. - Runs
STOP REPLICAand repeats both GTID reads and the containment check, closing the race where the SQL applier advances after the first check. - Runs
CHANGE REPLICATION SOURCE TOwith the configured credentials and TLS settings, withoutRESET REPLICA ALL. - Runs
START REPLICAand boundedly verifies the direct canonical hostname and both replication threads.
If containment fails, status becomes Blocked/GTIDDiverged and no unsafe
repoint occurs. A post-STOP containment failure leaves replication stopped.
Other bounded failures remain Pending/MutationFailed for a later safe retry.
This generic state is recorded in sourceHost, sourceConvergenceState, and
sourceConvergenceReason; it does not replace old-primary
recoveryState/divergentGtid reporting.
Dragonfly during failover
When spec.dragonfly.enabled=true, Dragonfly follows the MySQL failover group but remains best-effort cache/session state, not durable data.
During planned failover, Bloodraven inserts two Dragonfly phases before MySQL promotion:
WaitingForDragonflySynccaptures the source Dragonfly replication offset and waits for the target Dragonfly replica to catch up, bounded byspec.dragonfly.plannedFailover.maxSyncWait(default30s).PromotingDragonflyremoves the source pod'sshipstream.io/dragonfly-trafficlabel, promotes the target withREPLTAKEOVER, stamps the target asshipstream.io/dragonfly-role=master, and best-effort kills old-master clients so they reconnect through the active Dragonfly Service.
If sync or REPLTAKEOVER fails, spec.dragonfly.plannedFailover.onSyncTimeout controls the outcome. The default proceed continues MySQL promotion and records status.plannedFailover.dragonfly.sessionsPreserved=false. fail rolls back before MySQL promotion and leaves the original MySQL primary active.
During emergency failover, MySQL promotion is the priority. After MySQL promotion succeeds, the operator attempts to promote Dragonfly on the new MySQL active site within a bounded budget. It first tries REPLTAKEOVER to preserve sessions; if that fails, it falls back to REPLICAOF NO ONE, which restores a writable Dragonfly master but discards cache/session continuity. If Dragonfly is unreachable, MySQL recovery still completes.
The Dragonfly manager also handles Dragonfly-only failures. If the active Dragonfly master dies while MySQL remains healthy, the manager can promote the single healthy Dragonfly replica and leave status.activeSite for MySQL unchanged.
Old primary recovery
After an emergency failover, the old primary may come back online. The operator automatically detects this and takes action based on whether the old primary's data has diverged from the new primary.
Detection
On each poll cycle, if a site is read-only with no replication configured (the signature of a former primary after RESET REPLICA ALL), and a prior failover has occurred, the operator initiates recovery:
- Fence the returning site with
SET GLOBAL super_read_only=ON(defensive — the sidecar may have already fenced it) - Query
@@global.gtid_executedon both the old and new primary - Compare GTID sets to determine if the old primary has any transactions not on the new primary
If the old primary returns writable (e.g., power was cut before the sidecar could self-fence), the operator first detects this as a split-brain condition and fences it immediately. Recovery proceeds on the next poll cycle once the site transitions to read-only.
No divergence (automatic rejoin)
If the new primary's GTID set contains all transactions from the old primary, there is no data loss. The operator automatically reconfigures the old primary as a replica:
SET GLOBAL super_read_only=ONSTOP REPLICARESET REPLICA ALLCHANGE REPLICATION SOURCE TO ... SOURCE_AUTO_POSITION=1START REPLICA
While the sequence runs, status.sites[].recoveryState is RecoveryInProgress and the RecoveryPending condition is True with reason RecoveryInProgress. The operator keeps that state until MySQL reports healthy replication, then writes replicating=true and gtidExecuted for the read-only site and clears recovery state.
Divergence detected (manual intervention required)
If the old primary has committed transactions that never replicated to the new primary, the operator:
- Keeps the site fenced (
super_read_only=ON) - Records the divergent GTID set and transaction count in
status.sites[].divergentGtidandstatus.sites[].divergentTransactionCount - Sets
status.sites[].recoveryStatetoRecoveryBlocked - Sets the
RecoveryPendingcondition toTruewith reasonDivergentTransactions - Emits the
bloodraven_divergent_transactionsPrometheus metric
Divergent transactions mean the old primary accepted writes that the new primary never received. These transactions are effectively lost from the replication stream. The site must be re-cloned from the current primary to recover. Do not attempt to manually reconfigure replication — conflicting GTID sets will cause replication errors.
To recover a divergent site:
-
Investigate the divergent transactions to understand what data was lost (check
status.sites[].divergentGtid) -
Trigger a reclone using the annotation, including the first 8+ characters of the observed
divergentGtidas a confirmation token:# Read the divergent GTID first:kubectl get mysqlfailovergroup <name> -o jsonpath='{.status.sites[?(@.name=="<site>")].divergentGtid}'# Then annotate with <site>:<prefix-of-divergentGtid>:kubectl annotate mysqlfailovergroup <name> bloodraven.shipstream.io/reclone-site=<site>:<gtid-prefix> -
The operator validates that the prefix matches the observed
divergentGtid— a mismatch is rejected with aRecloneRejectedWarning Event, so a fat-fingered site name can't destroy the wrong replica. When a site has nodivergentGtid(cold reclone: PVC loss, manual rebuild), usekubectl bloodraven reclone <group> <site> --coldto provide the required destructive confirmation. -
The operator runs
CLONE INSTANCEon the target site, replacing all data with a fresh copy from the current primary. ARecloneRequestedEvent marks the start.
See Recovering a divergent old primary for the full procedure.
Prerequisites
Old primary recovery requires replication credentials (MYSQL_REPLICATION_USER and MYSQL_REPLICATION_PASSWORD) in the Secret referenced by spec.secretName. Without these, recovery is skipped and the site remains fenced.
Split-brain resolution
When the state machine observes both sites as writable simultaneously, the operator's response is tiered:
- After a prior operator-initiated failover -- The operator already knows which site it promoted (
status.lastFailoverTarget). The other site being writable means the old primary returned. The operator fences it immediately (SET GLOBAL super_read_only=ON) and recovery proceeds on the next poll. This runs regardless ofspec.splitBrainPolicy. - No prior failover history,
spec.splitBrainPolicy.preferSiteis set -- The operator fences the non-preferred site and re-promotes the preferred one through the standard failover path (relay-log drain,RESET REPLICA ALL, promotion GTID record,read_only=0, writable confirmation, DNS flip). The anti-flap cooldown still applies to this promotion. - No prior failover history, no
preferSiteconfigured -- The operator alerts only (SPLIT BRAIN: both sites are writable) and takes no automated action. This is the default.
When preferSite applies
preferSite is a tiebreaker for states the operator cannot resolve from its own history. The two common triggers:
- Fresh deploy with existing data. Both sites come up writable and
lastFailoverTargetis empty because this operator instance has never failed anything over. WithoutpreferSite, the operator alerts and waits for an admin. - Operator restart amnesia. In-memory
lastFailoverTargetis repopulated fromstatus.lastFailoverTargetat startup, but if a split brain occurred during the restart window (for example, an old primary came back while the operator was restarting), the operator may never have had an opportunity to record the most recent failover.preferSiteprovides a deterministic answer in this case.
When history is available (case 1 above), the operator trusts it and does not consult preferSite. This preserves the invariant that the site most recently promoted keeps its writes.
Configuration
apiVersion: shipstream.io/v1alpha1
kind: MysqlFailoverGroup
metadata:
name: orders
spec:
sites:
- name: iad
# ...
- name: pdx
# ...
splitBrainPolicy:
preferSite: iad # "iad always wins ties"
preferSite must match one of spec.sites[].name; the CRD's CEL validation rejects mismatches at admission time.
Data-loss implications
preferSite is a policy decision, not a safety feature. When the operator fences the losing site to resolve a split brain:
- Any transactions committed on the losing site that did not replicate to the winner are isolated.
- Those transactions are not automatically replayed, merged, or preserved. They remain on the losing site's PVC but are outside the replication stream.
- When the fenced site attempts to rejoin, Bloodraven's existing divergent-GTID detection compares
executed_gtid_seton both sides. If the loser has GTIDs the winner never saw, rejoin is blocked and the site must be recloned to recover. The divergent GTID set and transaction count are recorded instatus.sites[].divergentGtidandstatus.sites[].divergentTransactionCount. - In other words,
preferSitemakes split-brain resolution fast and deterministic at the cost of silently losing the loser's unreplicated writes. The loss is surfaced loudly (RecoveryBlockedcondition,bloodraven_divergent_transactionsgauge) but not prevented.
Choose preferSite only when your operational model has a clear authoritative site -- for example, a primary region that you always want writes to land in, with the other region serving as a pure DR replica whose occasional writes during a split brain are acceptable to discard.
Observability
- Metric:
bloodraven_split_brain_auto_resolve_total{prefer_site="<name>"}-- counter, incremented each time the operator resolves a split brain by fencing the non-preferred site. - Log event:
split-brain auto-resolve: fencing non-preferred site per spec.splitBrainPolicy.preferSiteatwarnlevel, withpreferSiteandfencedSitefields. - The standard failover log, metric (
bloodraven_failovers_total), and DNS-flip metric (bloodraven_dns_flips_total) also fire, since split-brain resolution runs through the same promotion path.
Anti-flap cooldown
To prevent rapid failover oscillation (e.g., a flapping network link), the operator enforces a cooldown period between automatic failovers. The default is 5 minutes, configurable via spec.failoverCooldown.
During the cooldown:
- The operator continues to monitor both sites and update status
- Automatic failovers are suppressed
- Manual intervention can still be performed (see Operations)
The cooldown timer resets after each failover. The last failover time is recorded in status.lastFailover.
Ordered updates
When spec.updateStrategy is set to OrderedUpdate, spec changes (such as a new image, effective per-site MySQL config, or resource adjustments) are rolled out with zero downtime:
This sequence ensures:
- The active primary is never restarted while serving traffic
- Replication is healthy before each transition
- At most one site is unavailable at any time
For groups with more than two sites, every drifted non-active follower is
updated sequentially and must be read-only with a direct healthy source before
and after restart. If the active site has no drift, the rollout completes
without failover; this is the normal reader-only configuration path. If the
active site is drifted, only a healthy primary-candidate standby may receive
the handoff. A reader or dr-only follower is never promoted to facilitate an
update, and failed or unprocessed drift remains queued for a later reconcile.
Without OrderedUpdate, both sites are updated simultaneously, which may cause brief downtime if both pods restart at the same time.
For MySQL image changes, see the Upgrade and version-skew policy. The replica-first ordering above is the MySQL-required direction for a rolling version upgrade.