Failure-mode matrix
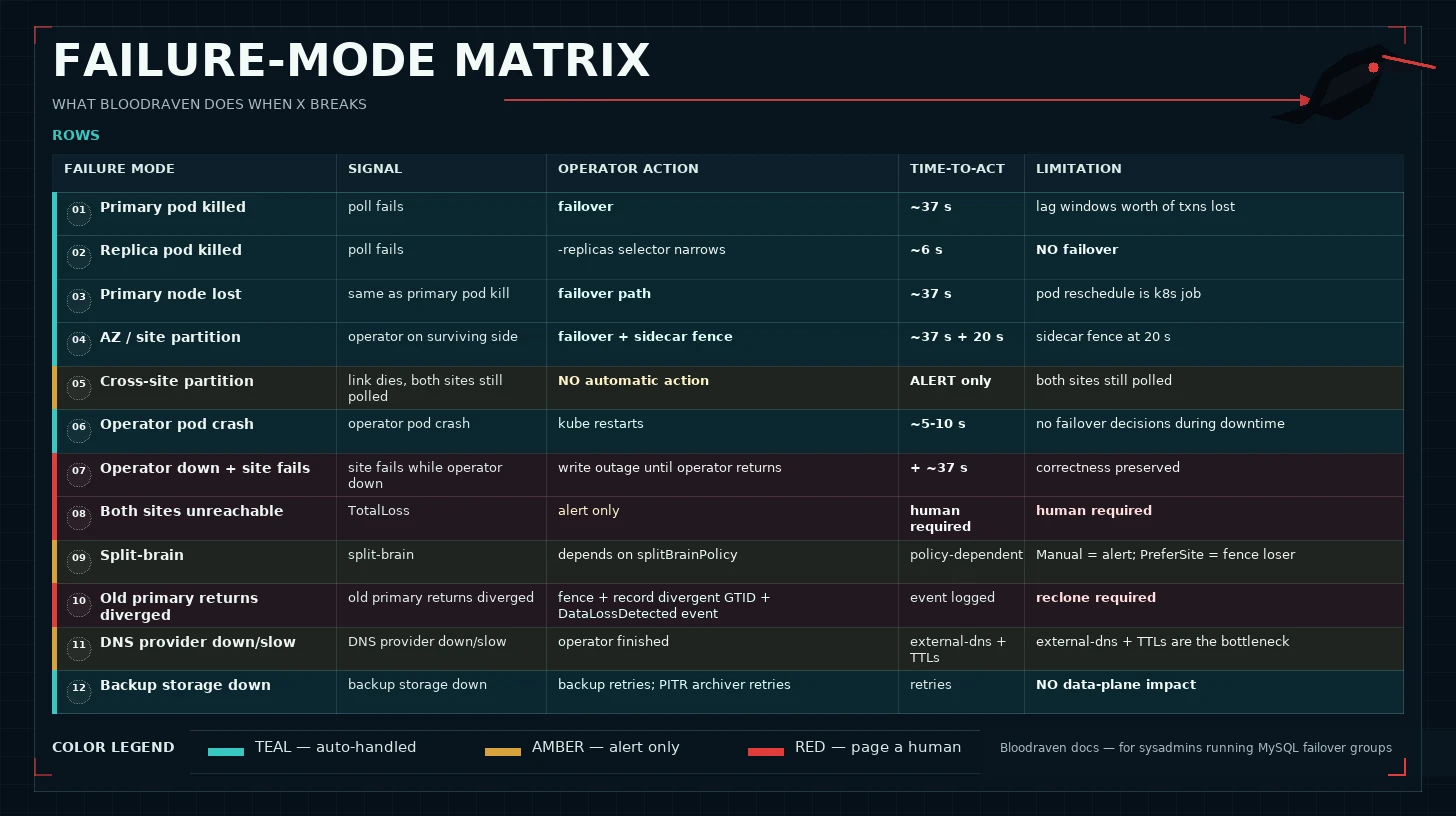
A single-table reference for "what happens when X breaks" — mapping common failure modes to the operator's detection signal, the action it takes, roughly when it acts, and what it will not do. Use this to cross-check an incident in progress against the operator's expected behavior, and to decide which alerts to carry.
Timing assumes the shipped defaults: spec.pollInterval=2s,
spec.failureThreshold=3, spec.failoverCooldown=5m, sidecar
spec.sidecar.leaseTimeout=20s. Tighter / looser values shift
everything proportionally.
Quick reference
| Failure | Observable signal | Operator action | Operator time-to-act | Operator limitations |
|---|---|---|---|---|
| Primary pod killed | MySQL poll fails on primary; pod NotReady. | Debounces to unreachable → promotes replica via failover sequence (fence old primary, drain relay, promote, flip DNS). | ≈ 6 s (detection) + up to 30 s (relay drain) ≈ 37 s total. | If replica is lagging, the lag interval's worth of committed transactions is lost. If the primary pod respawns inside 6 s, no failover — the pod is back too fast to debounce. |
| Replica pod killed | Poll fails on replica; replica becomes unreachable and Degraded=True with reason Alert. | Marks replica unreachable; narrows the -replicas Service selector to exclude it. No failover — the primary is still writable. | ≈ 6 s. | Read-only workloads hitting the -replicas Service lose endpoints until the replica returns. Backups fall back to the primary (controlled by maxLagSecondsForSource). |
| Primary node lost | Primary pod goes NotReady + no node heartbeat. | Same as primary pod killed — fails over to the replica. Kubernetes separately reschedules the pod onto a healthy node. | ≈ 37 s for the failover. Pod reschedule is Kubernetes's job and depends on eviction policy (30 s – 5 min). | If the PVC is zone-bound (e.g. topology.kubernetes.io/zone-pinned EBS) and the lost node was the zone's only node, the pod cannot reschedule until capacity returns. The operator has already failed over; the zone-bound PVC problem is a Kubernetes concern. |
| Replica node lost | Poll fails on replica. | Marks replica unreachable; narrows -replicas selector. No failover. | ≈ 6 s. | Same as replica-pod-killed. Kubernetes reschedules the pod to another node with access to the PVC. |
| Primary PVC lost | Primary pod restarts into an empty MySQL or stuck bootstrap. GTID-empty detection fires on the next successful poll. | Fails over (if the primary was active) → after recovery, auto-clones the empty site from the current primary via CLONE INSTANCE. | Failover: ≈ 37 s. Clone duration depends on dataset size (minutes to hours). | Committed-but-unreplicated transactions on the lost PVC are unrecoverable. Auto-clone requires MYSQL_REPLICATION_USER/PASSWORD in the operator Secret (see Failover → Prerequisites). |
| AZ / site partition (operator can still reach the surviving side) | All poll targets at the isolated side time out; one side's pods go NotReady. | Fails over to the reachable site. Sidecar on the partitioned primary self-fences at T + leaseTimeout = T + 20 s, closing the split-brain window. | ≈ 37 s (failover) to the reachable side. Partitioned side is fenced at 20 s regardless of operator progress. | If the partitioned side had unreplicated transactions, they are "stranded" until the partition heals — at which point the operator detects divergentGtid and blocks recovery until an admin runs the reclone flow. |
| Cross-site partition (link between MySQL pods dies; operator still reaches both) | Replica's IO thread stops receiving events; Seconds_Behind_Source climbs. Eventually Degraded=True ReplicationLagging. | None automatic. The primary is still writable, the replica is still read-only. The operator alerts but does not fail over. | Alert at maxLagSeconds (default 300 s). | This mode is indistinguishable, from the operator's point of view, from "replica fell behind because of I/O pressure". Human judgement decides whether to force a failover. |
| Operator pod crash | up{job="bloodraven"} == 0. Liveness probe fails. CR status stops updating. | Kubernetes restarts the pod. On return, leader election resumes, polling resumes. | Pod restart ≈ 5–10 s. | No failover decisions happen during downtime. If the primary fails while the operator is down, writes are unavailable until the operator restart + a full failover sequence completes. Sidecars self-fence to preserve correctness. |
| Operator down + one site fails | Combined: operator liveness fails AND one MySQL site becomes unreachable. | Sidecars self-fence at T + leaseTimeout; no promotion happens until the operator returns, then it runs the normal failover sequence. | Operator-down duration + ≈ 37 s. | Write availability is lost for the operator-down window plus the post-restart failover. Correctness is preserved (no split-brain), but availability takes a direct hit. RPO is unchanged vs. the operator-up case. |
| Both sites unreachable (TotalLoss) | All polls to both sites fail. Degraded=True TotalLoss. | None. Emits TotalLossDetected Event and alerts. No automatic recovery is possible — nothing to fail over to. | Immediate after failureThreshold polls. | Requires human intervention. Once at least one site is back, the operator resumes; if both return, split-brain handling takes over. See Operations → Total loss recovery. |
Split brain (writable/writable) | Both sites poll as writable simultaneously. | Depends on spec.splitBrainPolicy. Default (Manual): alert via SplitBrainDetected Event; require human action. Opt-in (PreferSite): fence the non-preferred site. Post-operator-initiated failover: fence the returning stale primary immediately. | One poll cycle (≈ 2 s). | No automatic data-merge. If the fenced side accepted writes that the winning side doesn't have, those transactions surface as divergentGtid and require a reclone. See Failover → Split-brain resolution. |
| Old primary returns diverged | After a failover, the returning site has committed transactions the new primary never received. | Fences the returning site, records status.sites[].divergentGtid + count, sets RecoveryPending=True with reason DivergentTransactions, emits DataLossDetected Event. | One poll cycle after the site comes back (≈ 2 s). | Cannot auto-rejoin — divergent GTIDs would corrupt replication. Admin must run the reclone flow; the operator enforces the confirmation interlock on the annotation. See Failover → Divergence detected. |
| DNS provider down / slow | DNSEndpoint CR updates succeed, but application DNS lookups still return the old A-record. | Operator writes the new DNSEndpoint on failover and moves on — DNS propagation is external-dns's job, not the operator's. | CR update happens within the failover sequence (a few seconds). External-dns reconcile time and your DNS provider's TTL decide the app-visible delay. | The operator cannot accelerate DNS propagation. Applications should use short TTLs (spec.dns.ttl, default 60 s) and not cache MySQL connection addresses longer than the TTL. Monitor external-dns independently; a stuck external-dns is an outage for writes even after the operator has "finished". |
| S3 (or backup storage) unreachable | Backup Jobs fail; bloodraven_archiver_upload_failures climbs; bloodraven_archiver_backlog_files > 0; PITR lastUploadAt stops advancing. | Backup reconciler retries per spec.backup.retry. PITR archiver retries on every scan (archivePollInterval, default 60 s). | Retry backoffs are bounded by the retry spec; next archival attempt is one poll away. | No data-plane impact — MySQL keeps serving writes. PITR RPO silently drifts as unarchived binlogs accumulate. Alert on bloodraven_archiver_backlog_files > 0 sustained. See Monitoring. |
| Anti-flap cooldown blocks needed failover | Second failover condition arises within failoverCooldown of the previous one. | Operator logs failover blocked by anti-flap cooldown and does not fail over. | No automatic action until the cooldown expires (default 5 min). | The planned-failover API also honours this cooldown and will be rejected with reason: CooldownActive. If you genuinely need a second failover inside the cooldown window, perform a manual promotion — that path bypasses the cooldown explicitly. |
| Planned failover target fails to catch up | Admin annotated bloodraven.shipstream.io/planned-failover=<site>; target's GTID_EXECUTED does not cover source's fenced GTID within maxLagWait. | Operator unfences the source, stamps status.plannedFailover.phase: Failed with reason: LagTimeout, emits PlannedFailoverFailed Event. role=primary label is restored; no DNS flip occurred. | maxLagWait (default 5 min). | No data loss; cluster returns to pre-annotation state. Retry after replication has caught up, or use emergency failover if the source is truly gone. See Planned failover → Rollback. |
| Dragonfly master killed | spec.dragonfly.enabled=true; status.dragonfly.activeSite is unreachable, and one replica is reachable and not syncing/loading. | Promotes the replica with REPLTAKEOVER or fallback promotion, updates Dragonfly role/traffic labels, and leaves MySQL status.activeSite unchanged. | Next Dragonfly manager poll plus promotion budget. | Cache/session continuity is best-effort. If no healthy Dragonfly replica exists, the active Dragonfly Service may have no endpoints until recovery. MySQL availability is unaffected. |
| Dragonfly unavailable during MySQL emergency failover | MySQL primary is failed, and Dragonfly target/source cannot be reached or promoted. | Completes MySQL failover first. Dragonfly promotion is attempted best-effort and may record bloodraven_dragonfly_promotions_total{result="failed"}. | MySQL path remains ≈ 37 s; Dragonfly attempt is bounded separately. | Sessions/cache may be lost or unavailable. Dragonfly never blocks emergency MySQL recovery. |
| Planned Dragonfly sync timeout | Planned failover enters WaitingForDragonflySync, but the target Dragonfly replica does not reach the source offset within maxSyncWait. | With onSyncTimeout=proceed (default), promotes MySQL and stamps sessionsPreserved=false. With onSyncTimeout=fail, rolls back before MySQL promotion. | spec.dragonfly.plannedFailover.maxSyncWait (default 30 s). | proceed preserves MySQL availability at the cost of cache/session continuity. fail preserves the old active site and avoids claiming session preservation. |
| Replication credentials missing / wrong | Auto-clone fails; Bootstrapping condition stays in Failed. | Operator reports the failure via the Bootstrapping condition and events; does not keep retrying indefinitely. | Immediate (on the first bootstrap attempt). | Without MYSQL_REPLICATION_USER / MYSQL_REPLICATION_PASSWORD, old-primary recovery and auto-clone are both disabled. The rest of the operator (polling, failover, DNS) keeps working. |
Backup encryption failure modes
These rows apply only when a backup profile has spec.backup.profiles[].encryption
set. See Backup encryption for the full threat model.
| Failure | Detection path | Operator action | Typical time-to-act | Notes & limits |
|---|---|---|---|---|
| Passphrase Secret missing at restore time | Restore Job init container can't mount spec.initFromBackup.decryption.passphraseSecret; kubectl describe pod shows CreateContainerConfigError. | Reconciler records DecryptionSecretMissing on the restore CR; stops creating retry Jobs after backoffLimit. | Seconds (Job pod fails to start). | Recovery: recreate the Secret with the original passphrase value, or delete & re-apply the restore CR. Ciphertext is unrecoverable without the exact passphrase used at backup time — treat the Secret as critical recovery material. |
| Passphrase rotated between backup and restore | decrypt-download init container exits non-zero with a chunk-auth failure from backupcrypto. | Job pod's logs show backupcrypto: chunk 0: cipher: message authentication failed; reconciler reports DecryptionFailed. | Immediate on first read. | AES-GCM catches mismatched keys cleanly — there's no silent garbage load. Recovery requires producing the old passphrase; there is no re-wrap path today. |
| Ciphertext truncated by S3 multipart abort | decrypt-download returns backupcrypto: ciphertext truncated before final chunk (ErrTruncated). | Job pod fails fast; reconciler reports BackupCiphertextTruncated. | Immediate. | ErrTruncated distinguishes "tail missing" from a generic auth failure. Recover by re-running the source backup and restoring from the replacement artifact. |
| Object has no BRV1 magic (tamper / downgrade) | decrypt-download returns sidecar: object missing BRV1 magic while encryption is required (ErrTamperedOrDowngrade). | Job pod fails fast; reconciler reports BackupDecryptionRejected. | Immediate. | Defends against an attacker with bucket write access overwriting ciphertext with attacker-chosen plaintext. Legacy mixed-encryption deployments migrating to encryption can opt back into the old passthrough behavior via BLOODRAVEN_ALLOW_PLAINTEXT_FALLBACK=1 (sidecar / decrypt-download init container) — time-bounded migration only. |
How to read this table for your on-call
Two common uses:
- "What's the operator doing right now?" Find the row matching the symptom, read the Operator action and time-to-act cells to set your clock for when the situation should resolve on its own. If the expected time has passed and nothing has changed, check the Operator limitations column.
- "Do I need to page a human?" Alert on the rows whose Operator action is "none automatic" (cross-site partition, total loss, split brain, DNS provider, S3). These are the cases where the operator has deliberately deferred to a human.
Related reading
- Failover → State machine — the per-site and cross-site truth tables that drive every row's Operator action cell.
- Failover → Failover sequence — the step-by-step sequence that produces the "≈ 37 s" number.
- Operations — runbooks for the rows where the operator action is "none automatic".
- Monitoring — the metrics and events each row's Observable signal column refers to.
- Production hardening — which rows here the hardening checklist is specifically guarding against.