Known limitations
This page is the short version of Bloodraven's current boundaries. Read it before writing production manifests so the failure and recovery model matches your expectations.
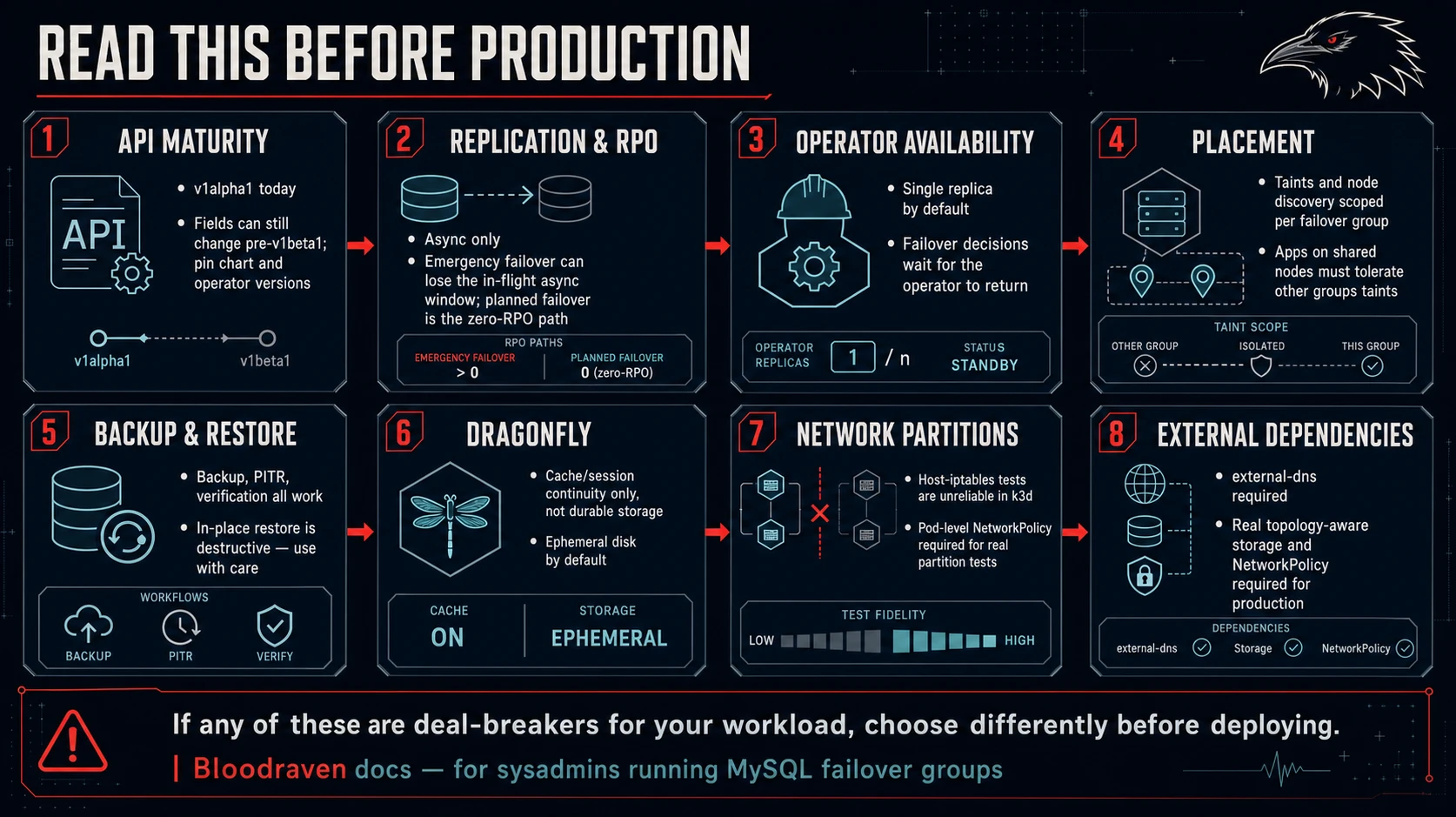
API maturity
- The CRD API version is
shipstream.io/v1alpha1. - Fields may still change before
v1beta1/v1. - There is not yet a published CRD conversion-webhook or migration contract. Track this under the CRD version-migration wishlist item.
Replication and RPO
- Bloodraven uses asynchronous MySQL replication. Emergency failover can lose transactions that committed on the old primary but had not reached the promoted replica.
- The operator records promotion and divergent GTID sets so data loss is observable, but it does not merge divergent data automatically.
- Planned failover is the zero-RPO path: it fences the source, waits for
the target's
GTID_EXECUTEDto cover the fenced source GTID, then promotes. - If you require synchronous commit semantics or quorum-based zero RPO on primary loss, Bloodraven is the wrong tool; see Why not Group Replication?.
- Read-only sites are full MySQL replicas. Filtered or partial replication, replication proxying, and query routing through an operator-managed proxy are not implemented.
- Clone and reclone copy from the active primary at full speed. Bloodraven does not throttle clone traffic, so adding or rebuilding a large reader can consume primary network, storage, and CPU capacity. Schedule the operation and monitor the donor accordingly.
Operator availability
- Leader election is enabled by the chart, but the default deployment still runs one replica. Run more than one operator replica only after validating the deployment model in your cluster.
- Sidecars preserve safety while the operator is unavailable, but new failover decisions wait for an operator to run.
- If the primary fails while the operator is down, writes remain unavailable until the operator returns and completes failover.
Placement and shared nodes
- Taints and node discovery are scoped per failover group with
spec.sites[].taintNodeSelector, so one physical node can advertise membership in multiple failover groups at the same site. - Application workloads on shared nodes must tolerate other groups' readonly taints but not their own group's taint.
Backups and restore
- Backup and PITR support is present, including backup verification, but restore-duration metrics and restore-performance guidance are still missing.
- In-place restore exists for destructive rollback of a live group. Use it carefully: full-instance restore fences writes and reclones the peer after loading the dump.
- PVC loss can be recovered by recloning from the current primary, but committed transactions that only existed on the lost PVC are gone. See Operations.
- Total cluster loss (all nodes and PVCs destroyed) requires recovering
into a separate Kubernetes cluster from the source backup archive.
See Multi-cluster DR for the end-to-end
runbook using
spec.initFromBackupwith optional PITR replay. read-onlysites cannot be selected for scheduled, automatic, or source-overridden backups. Healthydr-onlyfollowers remain eligible.
Dragonfly co-management
- Managed Dragonfly is optional and intended for cache/session continuity, not durable application state.
- Dragonfly pods use ephemeral storage unless you configure
spec.dragonfly.snapshotfor planned snapshot-restore maintenance. Bloodraven does not schedule Dragonfly backups as durable data backups. - Emergency MySQL failover never blocks on Dragonfly. If Dragonfly sync or promotion fails, sessions/cache may be discarded while MySQL recovery completes.
spec.tlsapplies to MySQL, not Dragonfly. Protect Dragonfly with NetworkPolicy, Dragonfly auth, and any external TLS/service-mesh controls your environment requires.
Network partitions
- The failure-mode matrix covers common partition classes, but a dedicated network-partition runbook with metrics/events for each asymmetric case is still missing.
- Playground partition tests must use pod-level NetworkPolicy or an equivalent mechanism; host-level iptables rules do not reliably block Kubernetes Service traffic in k3d.
Observability and tooling
- Grafana dashboards and metrics are shipped, but PrometheusRule alert examples are not yet packaged as first-class chart artifacts.
- The
kubectl bloodravenplugin wraps supported day-2 operations, but it remains a thin API client; the operator performs the authoritative safety checks.
External dependencies
- DNS steering depends on external-dns consuming
DNSEndpointobjects. Bloodraven updates the CR; DNS provider propagation time and TTLs are outside the operator's control. - Production installs need real topology-aware persistent storage. Local path / hostPath storage is acceptable for playground use only.
- The unauthenticated auxiliary and sidecar HTTP surfaces assume a trusted pod network. Use NetworkPolicy before exposing those Services broadly.