Multi-site topology
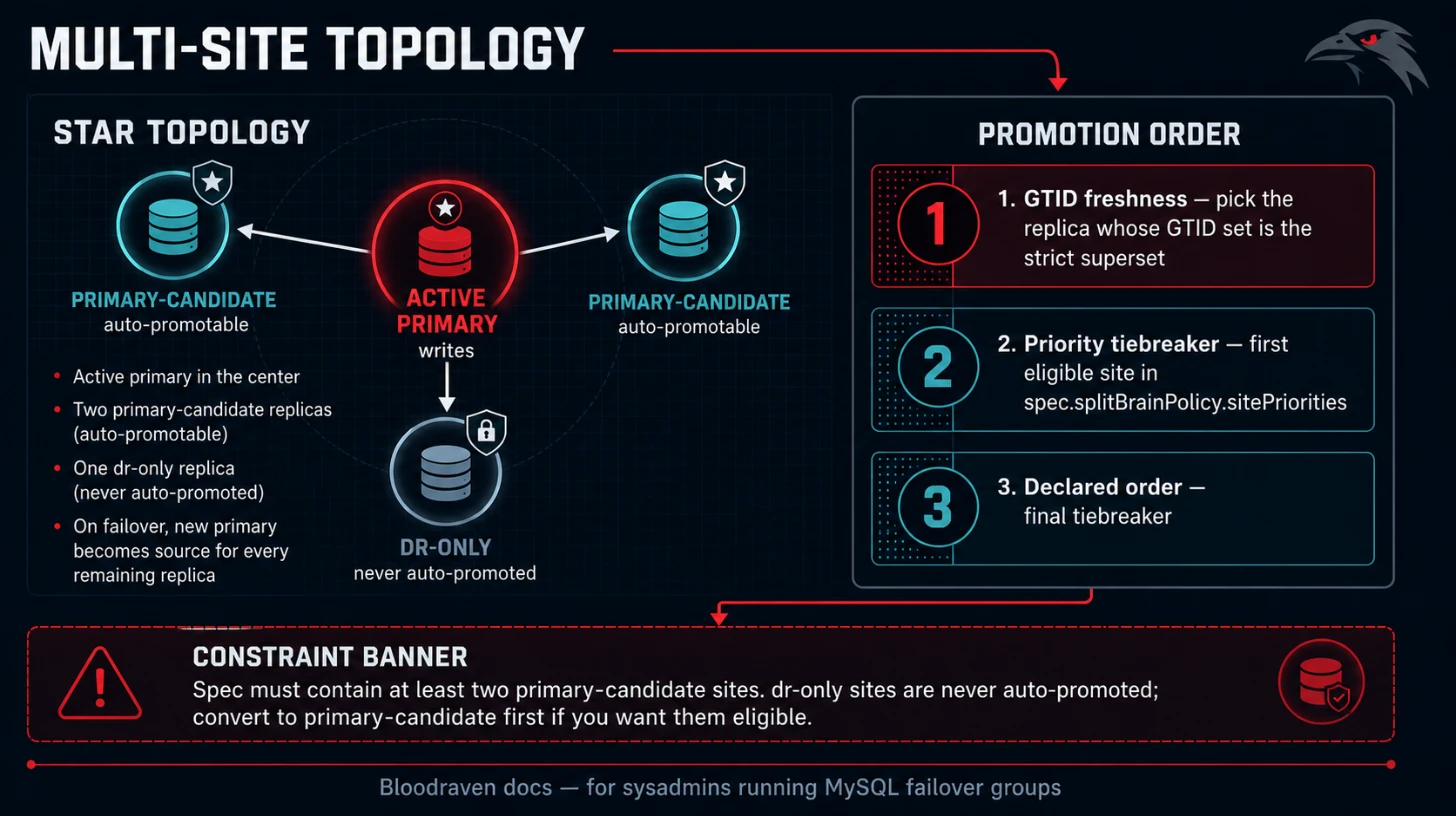
Bloodraven supports any number of sites (≥ 2) per MysqlFailoverGroup.
Each site declares a role that controls its behaviour during
failover:
| Role | Auto-promoted? | Typical use |
|---|---|---|
primary-candidate (default) | yes | active/standby pair inside a region |
dr-only | no | cross-region follower, kept for disaster recovery |
read-only | no | site-specific application read pool |
The spec must contain at least two primary-candidate sites so the
operator always has a promotion target for the current primary. Any
number of dr-only or read-only sites may be appended. A reader does
not count toward the two-candidate minimum.
Bloodraven uses these terms consistently:
| Term | Meaning |
|---|---|
| Reader | A site with effective role read-only. |
| Follower | Any non-active site with replication metadata, including candidate, DR, and reader sites. |
| Standby | A healthy, promotable primary-candidate follower. |
| Active primary | The unique observed writable site, which must have role primary-candidate. |
Replication topology
Bloodraven uses a star topology: one site is the active primary, and every other site replicates from it. There are no replication chains.
primary (iad, primary-candidate)
/ | \
/ | \
(pdx) (fra) (reader)
primary-candidate dr-only read-only
During planned or emergency failover, the newly promoted primary becomes the
direct source for every remaining follower, including dr-only and
read-only sites. Bloodraven also detects a healthy-looking follower that
still points through another replica after restart or topology drift.
Before repointing, the operator requires exactly one writable promotable
primary and checks that its GTID_EXECUTED contains the follower's executed
set. It repeats containment after STOP REPLICA to close the applier race,
then uses CHANGE REPLICATION SOURCE TO and START REPLICA without resetting
replication metadata. Divergence is reported as
sourceConvergenceState: Blocked with reason GTIDDiverged; Bloodraven does
not silently abandon follower transactions.
Failover target selection
When the active site becomes unreachable and at least one
primary-candidate replica is reachable, the operator promotes the
best candidate using this order:
- GTID freshness. The operator queries
@@gtid_executedon every eligible primary-candidate replica in parallel and picks the one whose executed set is strictly a superset of the others. This is the primary selector: promoting the freshest replica minimises transactions lost to the async-replication RPO window. - Priority tiebreaker. When multiple replicas have equivalent
GTID sets (common in healthy clusters), the first entry in
spec.splitBrainPolicy.sitePrioritiesthat is currently eligible wins. Entries not in the list fall through to declared site order. - Declared order. Final tiebreaker for replicas that share GTID sets and are not named in the priority list.
dr-only and read-only sites are never auto-promoted, selected by planned
failover, used as active DNS targets, or chosen as clone donors. A reader that
becomes writable is fenced on every topology poll, even if it is the only
writable site. Readers also never apply or remove node taints; supplied
lbIP and taintNodeSelector fields are accepted for manifest compatibility
but ignored.
If no primary-candidate replica is reachable when the primary
fails, the operator emits a NoPrimary alert and takes no action.
Manual promotion of a dr-only site is deliberately outside automatic
failover; convert it to primary-candidate first if you intend to make
it eligible for planned failover.
Split-brain resolution
spec.splitBrainPolicy.sitePriorities doubles as the split-brain
tiebreaker. When more than one site is simultaneously writable and the
operator cannot infer a winner from its own recent failover history
(for example, after a fresh deploy or an operator restart that lost
in-memory state), the first entry in sitePriorities that is
currently writable and primary-candidate is promoted; every other
writable site is fenced (SET GLOBAL super_read_only=ON).
If sitePriorities is empty — or if no entry in the list is currently
a writable primary-candidate — the operator alerts only and requires
manual resolution. This matches the default "don't guess" behaviour of
earlier Bloodraven versions.
Split-brain auto-resolution is a policy decision, not a safety feature. Writes accepted on losing sites that did not replicate to the winner are lost when those sites are fenced. The existing divergent- GTID detection will block auto-rejoin of any losing site whose GTID set contains transactions the winner never saw; those transactions are only recoverable via re-clone.
Example: three-site cross-region DR
Two in-region primary-candidate sites (active/standby HA) plus a
cross-region dr-only follower:
apiVersion: shipstream.io/v1alpha1
kind: MysqlFailoverGroup
metadata:
name: orders
spec:
sites:
- name: iad
role: primary-candidate
zone: iad-1a
taintNodeSelector:
shipstream.io/failover-group.orders: "true"
shipstream.io/site.orders: iad
lbIP: 10.0.0.10
storage: { storageClassName: gp3, size: 500Gi }
- name: pdx
role: primary-candidate
zone: pdx-1a
taintNodeSelector:
shipstream.io/failover-group.orders: "true"
shipstream.io/site.orders: pdx
lbIP: 10.1.0.10
storage: { storageClassName: gp3, size: 500Gi }
- name: fra
role: dr-only
zone: fra-1a
taintNodeSelector:
shipstream.io/failover-group.orders: "true"
shipstream.io/site.orders: fra
lbIP: 10.2.0.10
storage: { storageClassName: gp3, size: 500Gi }
splitBrainPolicy:
sitePriorities: [iad, pdx]
# ... rest of spec ...
Failover behaviour:
- If
iadgoes down,pdxis promoted (first priority, primary- candidate, reachable replica). - If
iadandpdxboth go down, the operator alerts — it will not auto-promotefrabecausefraisdr-only. Manual promotion would use the forthcoming planned-failover API. - If two sites become simultaneously writable (split-brain), the
winner is the first
sitePrioritiesentry currently writable; others are fenced.
Sidecar peer awareness
Each pod's sidecar is given the internal Service addresses for every
non-self site, including dr-only sites and readers, via the
PEER_ADDRESSES env var. The sidecar tracks per-peer liveness and only self-fences when
the operator and every peer are unreachable beyond
spec.sidecar.leaseTimeout. A single reachable peer is enough to
keep the primary writable.
This quorum rule matters as the number of sites grows: a split where the primary can still reach at least one peer is preserved as a legitimate-writes window rather than collapsing to a self-fenced outage.
Reader peers provide connectivity and relay fresh operator-authoritative active-site observations; they gain no promotion or primary authority. A reachable peer without fresh authoritative topology can still suppress the lease-only all-peers-unreachable fence. This is retained compatibility behavior, not a quorum guarantee.
Example: two candidates and a reader
The reader omits candidate/DR-only placement fields, uses a lower endpoint lag threshold, and customizes only its own client Service and MySQL config:
spec:
replication:
maxLagSeconds: 300
readOnlyMaxLagSeconds: 30
sites:
- name: iad
role: primary-candidate
zone: iad-1a
taintNodeSelector:
shipstream.io/site.orders: iad
lbIP: 10.0.0.10
storage: {storageClassName: gp3, size: 500Gi}
- name: pdx
role: primary-candidate
zone: pdx-1a
taintNodeSelector:
shipstream.io/site.orders: pdx
lbIP: 10.1.0.10
storage: {storageClassName: gp3, size: 500Gi}
- name: reader
role: read-only
zone: iad-1b
mysqlConf:
innodb_buffer_pool_size: 4G
serviceTemplate:
type: LoadBalancer
externalTrafficPolicy: Local
annotations:
service.beta.kubernetes.io/aws-load-balancer-internal: "true"
storage: {storageClassName: gp3, size: 500Gi}
splitBrainPolicy:
sitePriorities: [iad, pdx]
Sizing and compatibility
- Minimum: 2 sites, both
primary-candidate; readers are additional sites. - Maximum: 16 sites. Practical limits derive from replication cost on the primary (each replica opens an I/O thread) and from DNS/LB churn at failover time.
- Every site receives a Deployment, PVC, client MySQL Service, internal administrative Service, and per-site MySQL ConfigMap. Reader client endpoints have stricter health gating than other site Services.
Known limitations
dr-onlysites cannot be auto-promoted. Region-level loss of every primary-candidate site requires manual intervention.- Planned failover targets only
primary-candidatesites. Adr-onlyorread-onlysite must be deliberately reclassified, withlbIPandtaintNodeSelectorsupplied, before it can be promoted.