Network partitions
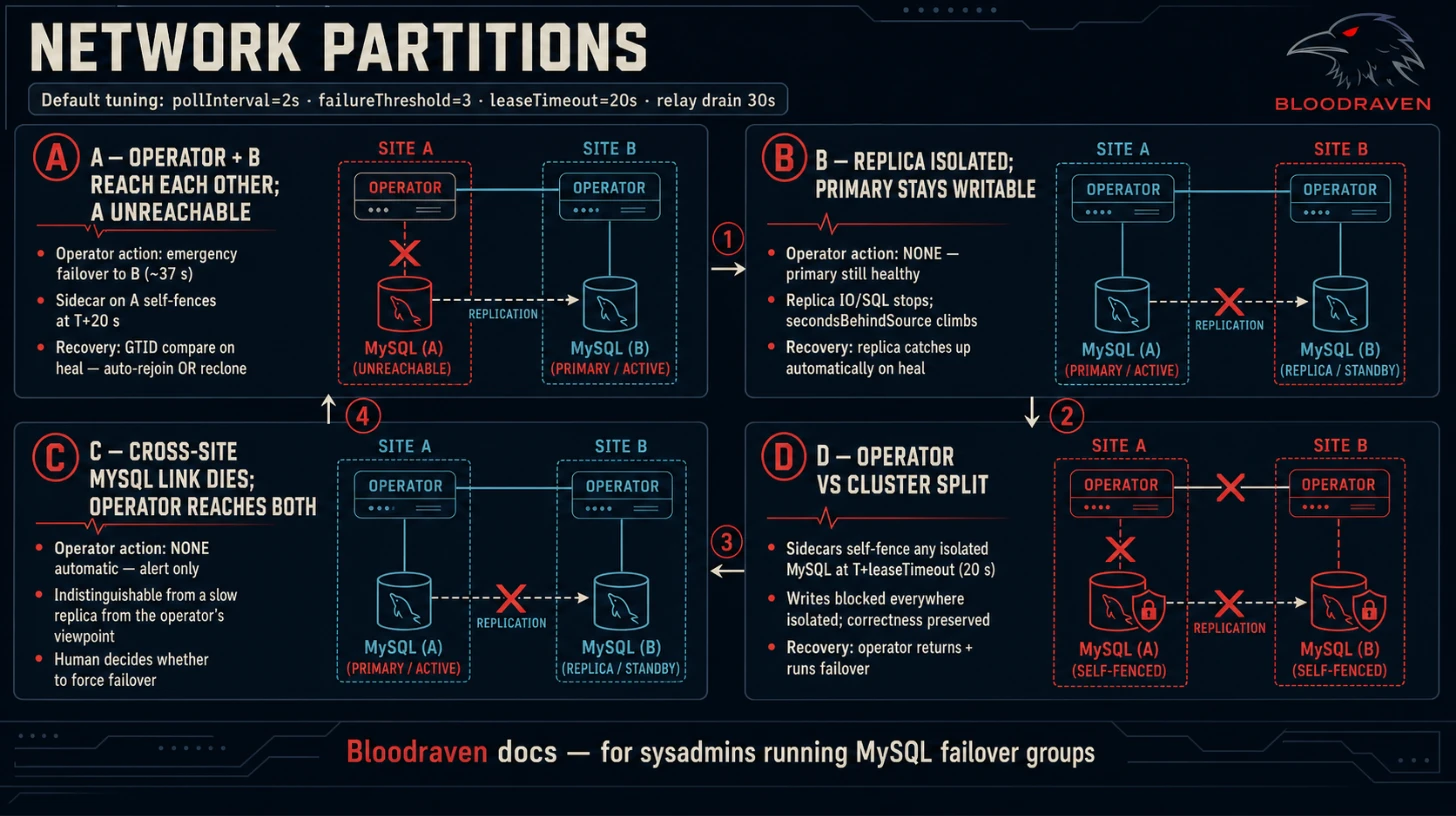
This runbook expands the network rows in the failure-mode matrix. It focuses on what the operator can observe, which action it takes, which metrics/events move, and what an operator should do after connectivity returns.
Timing assumes the defaults: pollInterval=2s, failureThreshold=3,
sidecar.leaseTimeout=20s, and a 30-second relay-log drain timeout.
First principles
- Bloodraven promotes only when the current primary is unreachable and a
promotable
primary-candidatereplica is reachable. - A replica-side network problem does not trigger failover while the primary remains writable.
- The sidecar self-fences a writable MySQL when it cannot reach the
operator and cannot reach any peer for longer than
leaseTimeout. - Cross-site replication lag is an alert, not a failover trigger, when the primary is otherwise healthy.
- Once a partition heals, GTID comparison decides whether the returning site can rejoin automatically or must be recloned.
Scenario A: operator cannot reach site A, site B reachable
Example: the active primary is iad; the operator and pdx are on the
surviving side of a site partition; all operator polls to iad time out.
| Aspect | Expected behavior |
|---|---|
| Observable signal | iad transitions to unreachable; pdx remains read-only and replicating until the link fully breaks. |
| Operator action | After debounce, promotes pdx via the normal emergency failover path, updates Services/DNS, and taints old-site nodes. |
| Sidecar action | If iad is still running but isolated from both operator and peers, its sidecar sets super_read_only=ON at roughly T+20s. |
| Metrics | bloodraven_site_state{site="iad",state="unreachable"}=1, bloodraven_failovers_total{target_site="pdx"} increments on successful promotion, bloodraven_dns_flips_total{site="pdx"} increments when DNS is updated, bloodraven_taint_operations_total{site="iad",action="taint"} increments. |
| Events | Expect the same failover lifecycle events as an unreachable primary: failover started/completed and, if the old primary later returns diverged, DataLossDetected. |
| RPO | Bounded by what had replicated to pdx before the partition. Any writes accepted only on iad after the partition are divergent when iad returns. |
Recovery after heal:
- Watch
status.sites[?(@.name=="iad")].recoveryState. - If there is no divergence, the operator reconfigures
iadas a replica automatically. - If
divergentGtidis set, review lost transactions and trigger the reclone flow in Operations.
Scenario B: replica site isolated, primary reachable
Example: active primary iad remains reachable by the operator;
replica pdx cannot receive replication traffic or cannot be polled.
| Aspect | Expected behavior |
|---|---|
| Observable signal | pdx becomes unreachable, or replication IO/SQL stops and secondsBehindSource climbs. iad remains writable. |
| Operator action | No failover. The primary is healthy, so promoting away would reduce availability and risk data loss unnecessarily. |
| Sidecar action | Replica sidecar does not self-fence a read-only MySQL; replicas are already not accepting writes. |
| Metrics | bloodraven_site_state{site="pdx",state="unreachable"}=1 or bloodraven_replication_lag_seconds rises; bloodraven_replication_running{site="pdx",thread="io"} may become 0. |
| Events | Degraded/alert events for unreachable or lagging replication; no failover-complete event. |
| RPO | Emergency failover is not available until a primary-candidate replica is reachable and reasonably current. |
Recovery after heal:
- Confirm replication restarts and lag falls below
spec.replication.maxLagSeconds. - If replication does not restart, inspect MySQL replica status and
operator logs for
old primary recovery failedor replication errors. - If the replica has been manually written to and now diverges, reclone it from the current primary.
Scenario C: MySQL-to-MySQL link broken, operator reaches both
Example: the operator can poll both iad and pdx, but pdx cannot
pull binlog events from iad.
| Aspect | Expected behavior |
|---|---|
| Observable signal | Primary remains writable; replica remains read-only; replica IO thread stops or lag increases. |
| Operator action | No automatic failover. From the operator's perspective this looks like replication lag or IO pressure, not primary failure. |
| Metrics | bloodraven_replication_running{thread="io"}=0 and/or bloodraven_replication_lag_seconds exceeds the configured threshold. |
| Events | Replication-lagging / degraded events; no DNS flip and no taint change. |
| Human action | Decide whether the link outage is temporary. If the primary is healthy, keep serving writes there. If you need to move writes, use planned failover only after the replica catches up. |
This is the scenario most likely to page a human without automatic action. Bloodraven intentionally refuses to guess that lag means the primary should be abandoned.
Scenario D: asymmetric peer reachability
Example: operator reaches both sites, iad can reach pdx, but pdx
cannot reach iad; or only one sidecar can reach its peer.
| Aspect | Expected behavior |
|---|---|
| Observable signal | Poll results can remain healthy while replication or peer checks show one-way failures. |
| Operator action | Follows the data-plane state it can poll: no failover while the active primary is reachable and writable. |
| Sidecar action | A writable primary self-fences only when both the operator and every peer are unreachable beyond leaseTimeout. One reachable peer is enough to avoid self-fencing. |
| Metrics | Usually replication lag/running metrics, plus possible state transitions if MySQL polling is affected. |
| Events | Degraded/replication events unless the asymmetry also makes the primary unreachable to the operator. |
Asymmetric partitions are exactly why GTID reconciliation after heal matters. If either side accepted writes that the final primary did not receive, the returning site is fenced and marked divergent.
Scenario E: both sites unreachable to the operator
| Aspect | Expected behavior |
|---|---|
| Observable signal | All sites become unreachable; Degraded=True with total-loss semantics. |
| Operator action | No promotion. There is no reachable candidate to promote. |
| Sidecar action | Any still-running writable site self-fences after leaseTimeout if it cannot reach operator or peers. |
| Metrics | bloodraven_site_state{state="unreachable"}=1 for all sites; no failover counter increment. |
| Events | Total-loss / degraded events. |
| Human action | Restore at least one site or the operator network path. Once one site is reachable, the operator resumes normal reconciliation. |
Testing partitions
Use pod-level NetworkPolicy or CNI-native fault injection. Host-level
iptables rules in a k3d node are not reliable for Kubernetes Service
traffic because kube-proxy DNAT and pod networking happen in different
paths.
Playground examples live in playground/chaos-scenarios.md and use
NetworkPolicy-based partitions. Always run ./playground/chaos.sh recover
or delete the NetworkPolicy manually after a test.
On-call checklist
- Identify the current active site:
kubectl get mysqlfailovergroup orders -o jsonpath='{.status.activeSite}'. - Print per-site state:
kubectl get mysqlfailovergroup orders -o jsonpath='{range .status.sites[*]}{.name}: {.state} lag={.secondsBehindSource} recovery={.recoveryState}{"\n"}{end}'. - Check whether
bloodraven_failovers_totalincreased. If not, the operator likely chose to alert rather than promote. - If a site returns with
divergentGtid, do not manually attach it as a replica. Follow the reclone flow. - After recovery, verify replication lag is below your RPO threshold and that DNS/external-dns has converged if clients use external DNS.