Planned failover
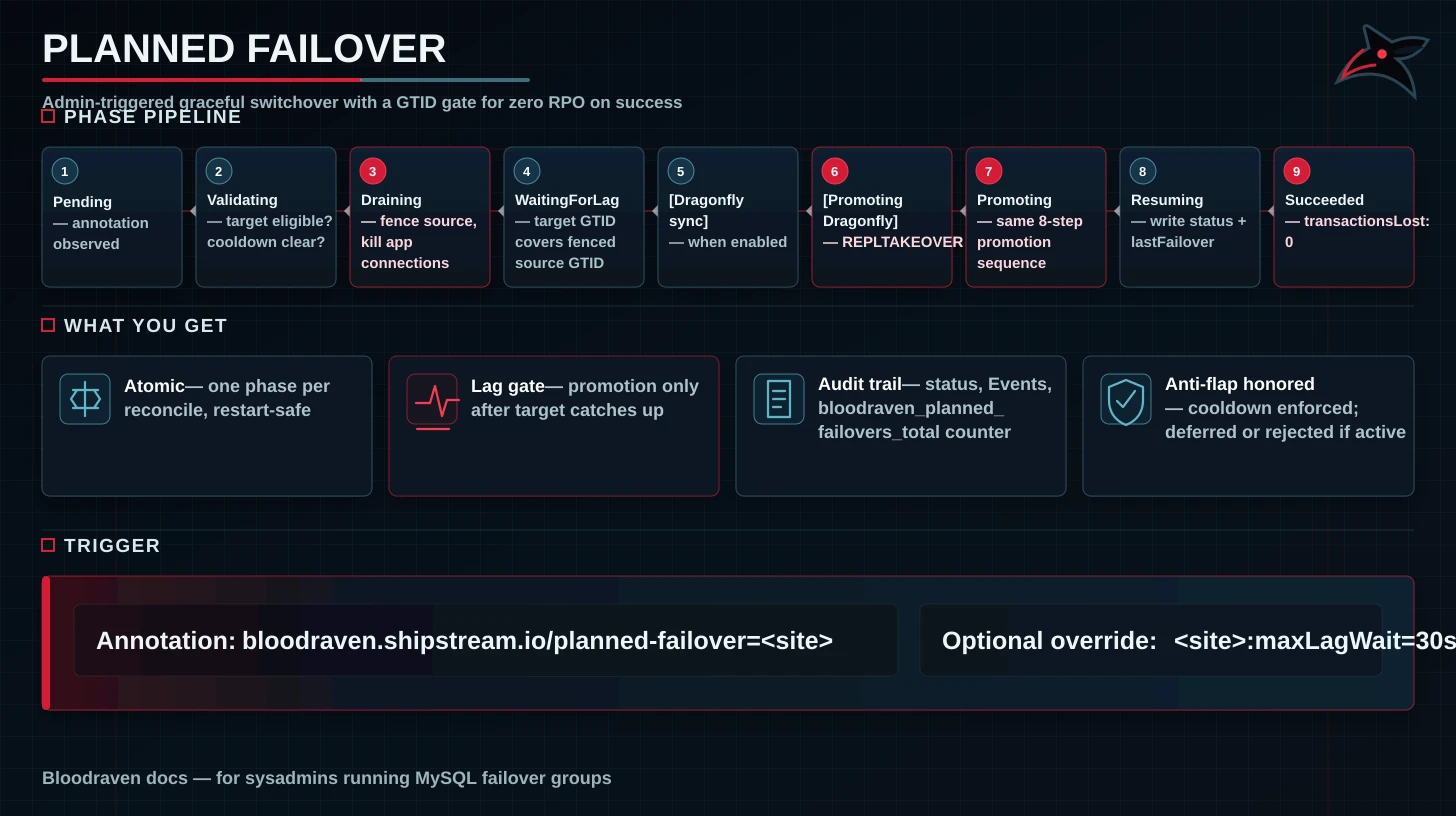
Planned failover is the admin-triggered graceful switchover path. It is the operational-hygiene counterpart to emergency failover: use it for maintenance windows, rolling kernel upgrades on the active site's nodes, or any time you want to move the primary role to a specific replica without relying on the operator's automatic detection.
TL;DR
kubectl annotate mysqlfailovergroup orders \
bloodraven.shipstream.io/planned-failover=pdx
The operator fences the current primary, waits for pdx to catch up on the fenced source's GTID set, promotes it, flips DNS, and clears the fence. When spec.dragonfly.enabled=true, the same request also waits for the target Dragonfly replica to catch up and promotes it before MySQL promotion. Status lands on .status.plannedFailover.phase: Succeeded with transactionsLost: 0.
Only primary-candidate sites are valid targets. dr-only and read-only
followers are never promoted, used for active DNS, or involved in node-taint
handoff. Readers remain direct followers and application read pools after the
switchover.
Why not kubectl exec?
Manual promotion via three kubectl exec ... SET GLOBAL ... commands (see Operations) works but has four real problems:
- No atomicity — a dropped connection or typo mid-sequence leaves the cluster fenced-on-both-sides or promoting a replica that has not drained its relay logs.
- No lag gate — nothing mechanical checks that the target is caught up before you flip
read_only=0. - No audit trail —
bloodraven_failovers_totaldoes not increment, no Event fires, no CR status reflects what you did. - Bypasses the anti-flap cooldown — a switchover immediately before a real emergency exposes the cluster to a window where the operator refuses to take automatic action.
The annotation API closes all four.
Lifecycle
Pending ──► Validating ──► Draining ──► WaitingForLag ──► WaitingForDragonflySync ──► PromotingDragonfly ──► Promoting ──► Resuming ──► Succeeded
│ │ │ │ │ │ │ │
│ └──► Deferred (cooldown active, onCooldown=defer) ──► re-enters Validating
│
└─ reject ────┴─ rollback ────┴─ rollback ────┴─ rollback/proceed ───────┴─ rollback/proceed ───┴─ fail ──────┴──► Failed
WaitingForDragonflySync and PromotingDragonfly are skipped when Dragonfly is disabled.
| Phase | What the operator is doing |
|---|---|
Pending | Annotation observed; status block initialised. |
Validating | Checking target is primary-candidate, replicating, read-only, no concurrent restore/update, cooldown not active. |
Deferred | spec.plannedFailover.onCooldown: defer is set and cooldown is still active. Annotation is retained; reconciler re-validates at status.plannedFailover.retryAfter. |
Draining | Two steps, one per reconcile: (1) SET GLOBAL super_read_only=ON on source + record sourceGtidAtFence, strip role=primary pod label so the -primary Service sheds endpoints; (2) KillAppConnections in a loop until idle or drainTimeout elapses. |
WaitingForLag | Polling the target's GTID_EXECUTED until it contains the source's fenced GTID set. |
WaitingForDragonflySync | When Dragonfly is enabled, captures the source Dragonfly replication offset and polls the target until it catches up or spec.dragonfly.plannedFailover.maxSyncWait expires. |
PromotingDragonfly | When Dragonfly is enabled, strips the source Dragonfly traffic label, promotes the target with REPLTAKEOVER, updates role/traffic labels, and best-effort kills old-master clients so they reconnect through the active Service. |
Promoting | Running the same promotion sequence as emergency failover: kill app connections, relay-log drain, STOP REPLICA, RESET REPLICA ALL, capture promotion GTID, clear super_read_only, SET GLOBAL read_only=0, verify the target is writable, then flip DNS. |
Resuming | Persisting status.activeSite, status.lastFailover, status.promotionGtidExecuted; releasing the topology-manager guard. |
Succeeded | Terminal success. Status block retained until the next annotation replaces it. |
Failed | Terminal failure. See rollback behaviour below. |
One phase transition per reconcile means operator restarts always land on a well-defined observable state — if the operator crashes during WaitingForLag, the next reconcile resumes the wait from the persisted sourceGtidAtFence.
Spec-level defaults
Cluster-wide knobs live on the CR so common overrides don't have to be spelled into every kubectl annotate:
spec:
plannedFailover:
maxLagWait: 5m # max time to wait for the target to catch up before rolling back
drainTimeout: 30s # upper bound on KillAppConnections polling after super_read_only=ON
onCooldown: reject # one of: "reject" (default) or "defer"
dragonfly:
plannedFailover:
maxSyncWait: 30s # Dragonfly target sync / REPLTAKEOVER budget
onSyncTimeout: proceed # one of: "proceed" (default) or "fail"
All fields are optional; omitting plannedFailover is equivalent to {maxLagWait: 5m, drainTimeout: 30s, onCooldown: reject}. Omitting dragonfly.plannedFailover is equivalent to {maxSyncWait: 30s, onSyncTimeout: proceed} when Dragonfly is enabled.
maxLagWait— how longWaitingForLagpolls the target before rolling back. Set shorter than the default when you know the cluster is caught up and want to fail fast.drainTimeout— upper bound on theDrainingphase'sKillAppConnectionsloop. Aftersuper_read_only=ON, the reconciler kills stragglers every second until the count reaches zero or the budget expires; advancing toWaitingForLaghappens either way so a stuck client cannot block the switchover.onCooldown— what happens whenValidatingrejects the request because the anti-flap cooldown is active:reject(default): stampFailed{CooldownActive}and clear the annotation. The admin must re-annotate after the cooldown expires.defer: stampDeferred, keep the annotation in place, and re-try validation automatically atstatus.plannedFailover.retryAfter. Useful when you want to queue a switchover immediately after an emergency event without manually waiting out the cooldown.
dragonfly.plannedFailover.maxSyncWait— how longWaitingForDragonflySyncwaits for the target Dragonfly replica to reach the source offset. The same duration is used as theREPLTAKEOVERtimeout.dragonfly.plannedFailover.onSyncTimeout— what happens when Dragonfly sync or promotion cannot prove session preservation:proceed(default): continue MySQL promotion and stampstatus.plannedFailover.dragonfly.sessionsPreserved=false.fail: roll back before MySQL promotion, release the MySQL fence, and leavestatus.activeSiteunchanged.
Per-request override
The annotation value may carry a maxLagWait override, mirroring the reclone-annotation key=value grammar:
kubectl annotate mysqlfailovergroup orders \
bloodraven.shipstream.io/planned-failover=pdx:maxLagWait=30s
Useful when you know the target is caught up and want to fail fast rather than wait five minutes for the default timeout.
Status
Inspect progress:
kubectl get mysqlfailovergroup orders \
-o jsonpath='{.status.plannedFailover}{"\n"}'
Example Succeeded block:
status:
plannedFailover:
phase: Succeeded
target: pdx
sourcePrimary: iad
sourceGtidAtFence: "abc-...:1-9182731"
targetGtidAtPromotion: "abc-...:1-9182731"
startTime: "2026-04-20T14:32:00Z"
completionTime: "2026-04-20T14:32:47Z"
durationSeconds: 47
transactionsLost: 0
dragonfly:
enabled: true
sessionsPreserved: true
promotionMethod: REPLTAKEOVER
syncWaitSeconds: 3
message: "promoted pdx, 0 transactions lost"
Rollback and failure modes
Every path out of Draining, WaitingForLag, or Promoting either completes a promotion or restores the old primary to writable. Below, rollback means the operator unfenced the source and left the cluster unchanged.
| Failure | Observable | Rollback? |
|---|---|---|
| Target is unknown / dr-only / read-only / not replicating | phase: Failed, reason: TargetUnhealthy or UnknownSite, event PlannedFailoverRejected | no fence applied |
Anti-flap cooldown active + onCooldown: reject | phase: Failed, reason: CooldownActive, message includes retry after ... | no fence applied |
Anti-flap cooldown active + onCooldown: defer | phase: Deferred, reason: CooldownActive, retryAfter populated; annotation retained | no fence applied; reconciler retries automatically |
Admin removes the annotation while Deferred | phase: Failed, reason: Cancelled | no fence applied |
| Concurrent in-place restore or ordered update | phase: Failed, reason: ConcurrentOperation | no fence applied |
| Zero-lag wait times out | phase: Failed, reason: LagTimeout, source unfenced, role=primary label restored, no DNS flip | yes |
drainTimeout elapses with clients still connected | Draining advances to WaitingForLag anyway with a message noting remaining connections | N/A — source is already fenced, clients get ER_OPTION_PREVENTS_STATEMENT on their next write |
Source crashes during Draining | phase: Failed, reason: SourceCrashed | hand-off to emergency failover path |
Dragonfly target fails to catch up and onSyncTimeout=proceed | phase advances through PromotingDragonfly, status.plannedFailover.dragonfly.sessionsPreserved=false | no MySQL rollback; MySQL promotion continues |
Dragonfly target fails to catch up and onSyncTimeout=fail | phase: Failed, reason: DragonflySyncTimeout, source unfenced, no DNS flip | yes |
Dragonfly REPLTAKEOVER fails and onSyncTimeout=proceed | status.plannedFailover.dragonfly.sessionsPreserved=false, reason: DragonflyPromotionFailed; MySQL promotion continues | no MySQL rollback |
Dragonfly REPLTAKEOVER fails and onSyncTimeout=fail | phase: Failed, reason: DragonflyPromotionFailed, source unfenced, no DNS flip | yes |
FailoverController.Execute fails mid-promotion | phase: Failed, reason: ExecuteFailed | no — same failure mode as emergency; manual recovery required |
| DNS flip fails | phase: Succeeded with a warning event | N/A — the Service label swap carries writes to the new primary while external DNS catches up |
The topology-manager's automatic cross-site evaluation is paused while a planned failover is in flight (via the plannedFailoverActive guard). When the planned path stamps Succeeded or Failed, the guard is released and the automatic path resumes.
Follower convergence after success
Once the target is confirmed writable and planned-failover mutation is no
longer in flight, Bloodraven converges every other candidate, dr-only, and
read-only follower directly to the new primary. A chained or stale source is
not considered healthy merely because its replication threads are running.
Before STOP REPLICA, the new primary's GTID_EXECUTED must contain the
follower's executed set. Bloodraven repeats this check after STOP to close the
SQL-applier race, then changes the source and starts replication without
resetting replication metadata. A failure is retried boundedly on subsequent
polls. GTID non-containment is reported per site as
sourceConvergenceState: Blocked and
sourceConvergenceReason: GTIDDiverged; the operator does not discard the
follower's extra transactions or silently repoint it.
Reader client endpoints remain absent until MySQL is read-only, both threads
are healthy, direct-source convergence is Converged, and known lag is within
the effective reader threshold. A blocked or lagging reader does not change
the successful planned-failover result or the group's shared Ready/Degraded
conditions.
Anti-flap cooldown
The planned path writes status.lastFailover on success, exactly like the emergency path. This means:
- A planned failover within
spec.failoverCooldownof any prior failover is rejected atValidating. - An emergency failover within
spec.failoverCooldownof a planned failover is blocked by the same cooldown check in the topology manager.
The default cooldown is 5 minutes; production deployments should keep this, not lower it.
Observability
Metrics
| Metric | Type | Labels |
|---|---|---|
bloodraven_planned_failovers_total | counter | target_site, result (success, rejected, failed_timeout, failed_other) |
bloodraven_planned_failover_duration_seconds | histogram | target_site |
bloodraven_planned_failover_lag_wait_seconds | histogram | target_site |
bloodraven_dragonfly_promotions_total | counter | group, target_site, result (success, failed, skipped) |
bloodraven_failovers_total (automatic only) and bloodraven_dns_flips_total retain their existing semantics. Dashboards keyed on bloodraven_failovers_total see no change.
Events
PlannedFailoverStarted, PlannedFailoverSkipped (already-active target), PlannedFailoverRejected, PlannedFailoverDeferred (cooldown + defer policy), PlannedFailoverDraining, PlannedFailoverLagOK, PlannedFailoverCompleted, PlannedFailoverFailed, DragonflyPromotionStarted, DragonflyPromotionCompleted, DragonflyPromotionFailed, and DragonflySyncTimeout.
RPO
Planned failover is the one Bloodraven operation with an RPO of zero by construction. The zero-lag gate at WaitingForLag guarantees the target has replicated every committed transaction on the fenced source before promotion. Any scenario that would produce loss (target falls behind, source crashes mid-drain, catch-up times out) routes to the Failed rollback path instead of promoting a lagging replica. See Durability and RPO.